

[기술적 해법(Technical Insights) | Normalize Address and Detect Duplicates]
원문 출처: https://www.arbutussoftware.com/en/technical-insights/normalize-addresses-and-detect-duplicates
Arbutus Analyzer 의 Function(함수)를 사용하여, 주소를 정규화(Normalize Addresses)하고 숨겨진 중복(hidden Duplicates)을 탐지하는 방법.
이 자료에는 Analyzer 에서 직접 실행하는데 필요한 file, script 및 지침(instruction)이 포함되어 있습니다.
두 가지 예를 살펴보겠습니다.
첫 번째는 single file(단일 파일)을 사용하는 경우고,
두 번째는 두 파일의 정규화된 주소(normalized addresses)를 비교하는 경우입니다.
어떤 통제 리스크(control risk)를 해결할 수 있을까요?
- 공급업체 관리 통제(Vendor management control)는 동일한 주소(same address)를 사용하는 여러 공급업체 또는 동일한 주소를 사용하는 공급업체(vendor)와 직원(employ)을 탐지하지 못할 수 있습니다. 따라서 부정 리스크(risk of fraud)가 발생할 수 있습니다.
- 최신 주소를 유지하기 위한 공급업체 관리 통제가 실패했을 수 있습니다.
- 컴플라이언스 통제(Compliance control)가 감시 목록(watch list)에 있을 수 있는 상대방을 탐지하지 못할 수 있습니다.
- 하나의 파일(One file)에서 동일한 주소(same address)의 여러 인스턴스 식별(예: vendor/공급업체)
- 두 파일(Two files) 간의 가능한 주소 일치(address match) 식별(vendors-employees 또는 vendors-watch lists/공급업체-직원 또는 공급업체-감시 목록)
우리는 데이터를 정리하고 잠재적인 이중 청구 부정(double-billing fraud)을 식별하기 위해 Vendor master file(공급업체 마스터 파일)에서 중복된 주소(duplicate address)를 탐지하고자 합니다.
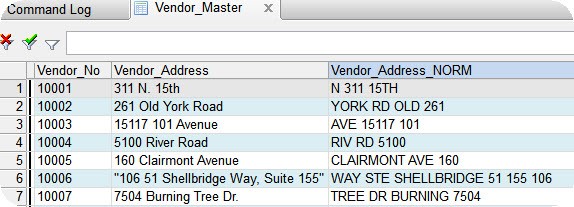
주소를 정규화(Normalizing the address)하여 비교가 용이하도록 한 다음, 기록된 주소가 아닌 정규화된 주소(normalized address)에서 중복(duplicate)을 찾습니다.
부정 범죄자(Fraud perpetrator)가 주소를 다르게 표시하여 자신의 노력을 은폐하려고 할 수 있기 때문에 주소를 정규화(normalize the addresses)하는 것이 중요합니다.
- 공백(Blank)을 제외한 알파벳/숫자가 아닌(non-alphanumeric) 모든 문자(character) 제거
- 모든 국제 문자(accent/강조점 포함 등)를 영어 기본 문자(English base character)로 대체
- 선행 공백(leading blanks) trim(자르기) 처리
- 연속 공백(Contiguous blanks)을 하나의 공백으로 압축
- 나머지 데이터에는 대문자(upper-case)를 사용
- 데이터 내 값(value)의 대체 유효한 표현을 표준화할 대체 파일을 하나 이상 지정(예: "Road"의 경우 "Rd", "Street"의 경우 "St") - 다운로드에서 "ADDR.txt" 파일 참조
- 공백(Blank)으로 구분된 나머지 정규화된 전체 단어(숫자 집합/number set 포함)를 descending order(내림차순)로 sort(정렬)
- Duplicates command(중복 명령)
- Join command(조인 명령)
이것은 두 개의 단어 열(columns of word)이 있는 간단한 text file 입니다.
왼쪽에 있는 단어들은 약어(abbreviations)를 포함하여 대부분의 주소에서 찾을 수 있는 단어입니다.
오른쪽에 있는 단어들은 SortNormalize()에 의한 변환 결과입니다. 예를 들어, "avenue"의 다음 인스턴스는 모두 오른쪽 텍스트로 변환됩니다.
또한 "THE" 및 "OF"와 같이 목록에 파트너가 없는 "noise" 단어도 제거됩니다.

이것은 일반 text file 이므로, 사용자는 새 대체 쌍(replacement pair)을 포함하는 다른 줄(line)을 추가하여 쉽게 업데이트할 수 있습니다.
이 파일은 Arbutus project 폴더에 있는 경우에만 전체 경로 없이 computed field expression(계산된 필드 표현식)에서 참조할 수 있습니다.
텍스트 파일이 다른 위치에 있는 경우 전체 경로(full path)를 지정해야 합니다.
SortNormalize function(함수)을 사용하여, 주소를 변환할 computed field(Edit >> Table Layout >> Add a New Expression)를 파일에 생성합니다.
Expression(표현식)은 주소 대체 파일 ADDR.txt를 참조해야 합니다.
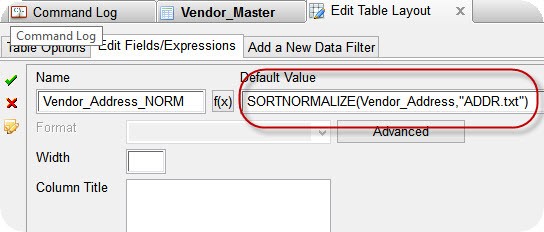
반드시 필요한 것은 아니지만, 비교를 위해 원래 주소 필드(address field) 옆에 있는 View 에 computed field(계산된 필드)를 추가할 수 있습니다.
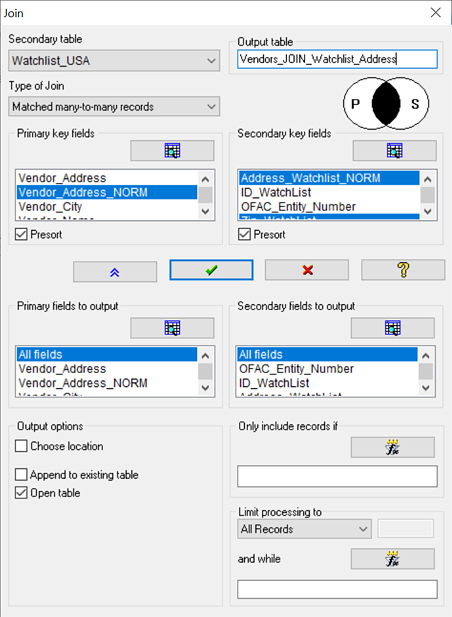
이 예에서는 vendor address(공급업체 주소)를 미국 감시 목록(US watchlist)에 있는 주소와 비교합니다.
- 두 파일 각각에 computed field(계산된 필드)를 생성합니다.
- 두 개의 새 computed field(계산된 필드)와 zip code(우편 번호)를 key field 로 사용하여, 두 파일 사이에 Matched Many-to-Many Join 을 만듭니다. (어떤 파일이 Primary 또는 Secondary 파일인지는 중요하지 않습니다.)
- "Primary fields to output" 및 "Secondary fields to output" 목록에서 출력(output)에 필요한 other fields(다른 필드)를 선택합니다.
- 출력 파일(Output file)의 이름을 지정하고 "OK"을 클릭합니다.
- 결과(Result)는 동일한 정규화된 매칭(normalized match) 항목을 모두 표시합니다. 가능한 일치(match) 항목은 나란히(side-by-side) 표시됩니다. Same vendor address(동일한 공급업체 주소)가 여러 watchlist address(감시 목록 주소)와 일치(match)할 수도 있고, 그 반대의 경우도 가능합니다.
Vendor(공급업체) 10088 은 3개의 감시 목록 주소(watchlist address)와 일치(match)합니다.

USA.FIL
USA.FMT
Master.FIL
Master-FMT
ADDR.TXT