

[기술적 해법(Technical Insights) | Data Quality Matters]
원문 출처: https://www.arbutussoftware.com/en/technical-insights/data-quality-management-0
모든 사람들이 "Garbage in, Garbage out"(GIGO)이라는 개념에 대해 들어보았지만, 우리 대부분에게 이것은 받아들여지기는 하지만 추상적인 개념입니다.
오늘 우리는 데이터 품질(Data Quality - DQ)을 더 자세히 살펴보고 GIGO 를 최소화하는 방법을 보여줄 것입니다.
** Garbage in, Garbage out"(GIGO): ‘쓸데없는 것이 입력되면, 출력되는 것도 쓸데없는 것뿐’이라는 뜻으로, 컴퓨터에 불완전한 데이터를 입력하면 불완전한 결과 값이 나올 수밖에 없다는 말.
데이터 품질 문제(Data Quality Matters)
문제점(The Problem)
이상적인 세상에서는, 모든 시스템에 가장 높은 수준(level)의 내장 DQ(Data Quality) 검사가 있지만, 슬프게도 이것은 거의 그렇지 않습니다. 여기에는 여러 가지 이유가 있을 수 있겠지만 다음과 같은 몇 가지 이유가 있습니다.

시사점(The Implications)
여기에서 GIGO(Garbage in, Garbage out- 불완전한 데이터를 입력하면 불완전한 결과 값이 나올 수밖에 없다)가 고개를 듭니다.
잘못된 데이터(Bad data)는 사용자가 찾은 결과(result) 또는 해당 데이터를 기반으로 한 의사결정의 품질에 쉽게 영향을 미칠 수 있습니다.
앞서 언급한 바와 같이, 어떤 오류(error)가 향후 분석 및 의사결정에 영향을 미칠지 정확히 사전에 예측하는 것은 매우 어려운 일입니다. 이는 오늘날 우리가 살고 있는 빅 데이터(big data)의 역동적인 시대에 특히 그렇습니다.
아마도 내일의 작업은 해당 요일(the day of the week) 또는 시간(the time of day)을 기준으로 합니다.
이 데이터는 새로운 분석(analysis)이기 때문에 과거에 테스트되지 않았을 수 있습니다.
분석가(Analyst)가 작업을 시작할 때 직접 테스트(적절한 툴이 있는 경우)해 볼 수도 있지만, 데이터를 신뢰하고 그 데이터가 잘못된 경우 결과(result)가 손상될 수 있습니다.
데이터 품질(Data Quality)과 그 중요성
Date(날짜)는 하나의 예에 불과하지만, DQ를 조사할 수 있는 수준(level)를 보여줍니다.
시스템의 많은 데이터 요소는 동일한 깊이의 DQ 이슈(issue)를 가질 수 있으며, 실제로 거의 모든 데이터 요소는 DQ 개선을 위한 약간의 기회를 제공합니다. 또한 데이터의 용도는 시간이 지남에 따라 변한다는 점을 기억하는 것이 중요합니다.
시스템이 구현(implementing)되었을 당시에는 상대적으로 중요하지 않았던 것이 현재 분석에 매우 중요해질 수 있습니다. 시스템이 구현되었을 시점에는 영업일이 아닌 날에 거래(transaction)가 예약되었다는 것은 중요하지 않았을 수 있지만, 이제는 해당 부정(fraud)을 식별하는 것이 매우 중요합니다.
한가지 접근 방식 - 사후 테스트(Testing After the fact)
전사적인 데이터(Enterprise data)가 서로 다른 환경에서, 서로 다른 시간에, 서로 다른 직원에 의해 생성되는 다양한 시스템을 포함하고 있다는 점을 고려해 볼 때, 모든 시스템을 대상으로 적절한 수준(level)의 기본 DQ가 있을 것이라고 기대하는 것은 다소 순진(naïve)할 수 있습니다.
대신에, 강력한 접근 방식으로 사후 데이터(the data after the fact)를 테스트할 수 있습니다.
사후 테스트(Testing after the fact) 하는 것은 전후 사정을 다 파악할 수 있는 이점을 얻을 수 있습니다.
시스템이 구현(implement)될 때 모든 데이터 조각에 대한 모든 잠재적인 사용을 예상하는 대신, 지금 새로운 DQ 테스트를 설계 및 실행하고 현재 분석에 영향을 미치는 데이터 품질 이슈(data quality issue)를 식별할 수 있습니다.
또한 분석 요구 사항이 변경되면(DQ 기대치로 인해) 원본 소프트웨어를 업데이트하는 비용이 많이 드는 단계를 수행하지 않고도 이러한 새로운 요구 사항을 확인할 수 있습니다.
발견된 이슈(issue)에 대한 대응은 심각도에 따라 달라집니다.
문제(Problem)를 무시하거나, 데이터를 보정하거나, 원본 시스템을 업데이트하여 오류(error)를 허용하지 않도록 할 수 있습니다. 각 오류 타입은 분석에 고유한 영향을 미치지만, 문제(issue)가 있음을 인식하는 것이 첫 번째 단계입니다.
데이터 품질 구현(DQ Implementation)
적절하게 구현된 DQ 프로그램은 다음과 같습니다.
- 관리 정보(Management information) 목적의 중요한 데이터가 항상 깨끗한지(clean) 확인하기 위해, 모든 전사적 애플리케이션(enterprise applications)에 대한 데이터를 사전에 모니터링하고 데이터 품질 문제-data quality issues(적절한 빈도로)를 리포트
- 조직의 변화하는 요구 사항을 충족하도록 쉽게 업데이트
- 개선된 데이터 품질 탐지(data quality detection) 및 리포트를 통해 더 나은 정보 시스템(information systems)을 달성
- 신뢰할 수 있고 정확한 전사적인 데이터(enterprise data)를 사용하여 더 나은 비즈니스 의사 결정 및 결과(decisions & outcomes)를 달성
오류(Error)는 어디서?
DQ 를 테스트할 때 데이터 웨어하우스(DW) 또는 데이터 마트(data mart)와 같은 데이터 저장소(data repository) 또는 소스 데이터(source data) 자체라는 두 가지 주요 소스가 있는 경우가 대부분입니다.
둘 다 다 다르며, 둘 다 확인하는 것이 중요합니다.
DW 는 분명 'clean(깨끗)'해야 하지만, 깨끗하다고 해서 그것이 옳다는 것은 아닙니다.
저장소-Repository(ETL) 로드 시 오류(error)가 발생하면 소스 데이터 오류 또는 문제를 쉽게 가려(mask) 잘못된 DW 내용을 초래할 수 있습니다.
소스 데이터를 봐야만 데이터 품질(data quality)을 알 수 있습니다.
간단한 설명 예제가 도움이 될 수 있습니다.
DW 테이블에는 외부 시스템에서 생성된 고객(customer)과 관련된 성별(sex) 필드가 포함될 수 있습니다.
DW 필드를 로드하는 논리는 소스:sex="M"이면 DW:gender="M"이고 그렇지 않으면 DW:gender="F"인 것처럼 간단할 수 있습니다. (** Sex: 생물학적 기준의 성 구분. Gender: 사회성에 따른 성 역할 구분.)
이것은 DW 에서 분명히 깨끗한 데이터(clean data)를 보장하지만, 모든 오류(error)를 female(여성)으로 잘못 표시하여 DW 사용에 심각한 영향을 미칠 수 있습니다.
입력 당시에 알려지지 않았거나 단순히 오타가 있었는지 여부는 살펴보지 않는 한 소스 시스템에 무엇이 있는지 알 수 없습니다.
소스 데이터를 살펴보면, "M" 또는 "F"를 포함할 것으로 예상되는 단일 문자 필드(single character field)일 것입니다.
그러나 소스 시스템은 이 필드의 유효성(validate)을 검사하지 않으므로 "m", "?", "U" 또는 "L"과 같은 타입이 포함될 수 있습니다.
소스 시스템의 품질을 식별하는 것은 모든 DQ 실행의 기본입니다.
데이터 읽기(Reading the Data)
소스 데이터(Source data)는 전통적으로 액세스하기 어렵기 때문에 웨어하우스(warehouse)가 진화한 이유 중 하나입니다. 이것이 바로 Arbutus 의 독보적인 역량이 중요한 이유입니다.
Arbutus 는 시스템의 사용 기간이나 데이터의 복잡성에 상관없이 모든 소스 데이터에 액세스할 수 있는 제품군을 제공합니다.
Arbutus 기술은 모든 관계형 데이터베이스(relational database)와 호환될 뿐만 아니라 더 중요하게는 기본 메인프레임 애플리케이션(native mainframe application)을 통해 귀사의 메인프레임의 모든 레거시 데이터(legacy data)에도 액세스할 수 있습니다.
여기에는 VSAM, IMS, DB2, ADABAS 및 가변 레코드 길이(variable record length)와 여러 레코드 타입을 가진 VSAM 및 flat file 이 포함됩니다!
데이터 품질 정의(Data Quality Definition)
간단히 말해, 데이터 품질(DQ) 오류는 해당 항목이 명시적 또는 암시적(explicit or implicit) 메타데이터 정의(metadata definition)와 일치하지 않음을 의미합니다.
명시적 정의(Explicit definition)의 예는 데이터가 숫자(numeric)인 반면,
암시적 정의(implicit definition)의 예는 직원 연령 필드(employee age field)가 16세보다 작거나 70세보다 커서는 안 된다는 것입니다
두 가지 타입의 문제는 중요한 의미를 가질 수 있습니다.
데이터 품질 범주(Data Quality Categories)
DQ 오류에 대해 일반적으로 허용되는 IT 프레임워크는 다음과 같습니다.
정확하기는 하지만, 이러한 범주는 다소 추상적이라고 생각할 수 있습니다. 대신 다음과 같은 데이터 범주(data category)를 고려할 수 있습니다.
- 유효하지 않은(Invalid)
- 부적절한(Improper)
- 불완전한(Incomplete)
- 불일치한(Inconsistent)
데이터 품질(Data Quality) 예제
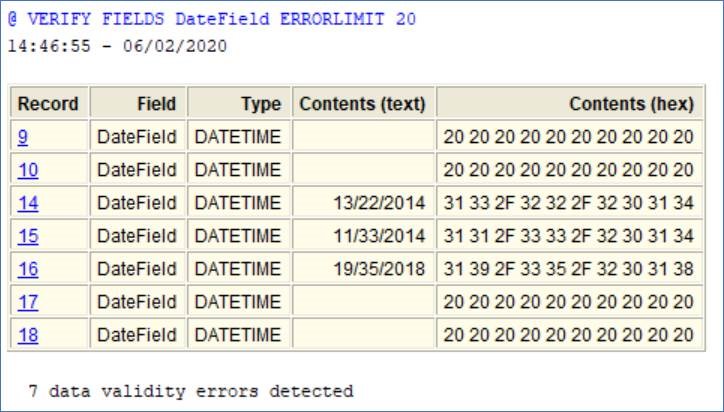
유효하지 않은 데이터(invalid data)는 정의된 필드(defined field) 타입과 일치(match)하지 않습니다.
데이터가 숫자(numeric)여야 하지만, 실제로 "UNKNOWN"이 포함된 경우 데이터는 유효하지 않은 데이터(invalid data)입니다.
아래의 경우 DateField(날짜 필드)에 잘못된 데이터가 있습니다. 공백 및 말도 안 되는 날짜가 감지되었습니다.
불완전한 데이터(Incomplete data)의 또 다른 일반적인 예는 key value(키 값)를 다른 테이블과 일치(matching)시키는 것과 관련됩니다.
예를 들어, 모든 고객 거래(customer transaction)에는 고객 마스터 파일(customer master file)에도 표시되는 고객 번호(customer number)가 있어야 합니다.
이러한 타입의 오류(error)를 식별하면 누락된 고객 마스터 레코드뿐만 아니라 거래(transaction) 또는 마스터 파일 키(master file key) 자체의 DQ 문제도 포착할 수 있습니다.
데이터 품질 검색(Data Quality Discovery)
자! 해봅시다(JUST DO IT)
어떤 범주(category)를 선호하든, Arbutus 를 사용하면 이러한 모든 특성을 완벽하게 테스트하고, 진행 중인 테스트를 자동으로 예약(automatically schedule)할 수 있습니다.
적절한 프로세스를 통해 시간이 지남에 따라 더 신뢰할 수 있고 정확한 데이터(trusted & accurate data)를 일관되게 확보할 수 있을 뿐만 아니라, 지속적이고 시기 적절한 발견(finding)을 통해 전반적인 정보 시스템(information systems)을 개선할 수 밖에 없습니다.