[군집분석(Clusters), 이상치(Outliers), 감성분석(Sentiment Analysis) 기능 살펴보기 - V9 릴리즈]
Sentiment Analysis(감성분석) | Clusters(군집분석) | Smart Query | Data Categorization | Outliers(이상치)
Arbutus 9 는 통찰력(insights), 예측(predictions) 및 고급 분석(advanced analytics)을 위한 AI/ML 분석 기능을 제공하며, 데이터 보안(data security)과 사용자 친화적인 디자인을 갖추고 있습니다. 모든 규모의 비즈니스에 맞게 원활하게 통합되고 확장됩니다.
- ML02 Outliers (이상치) 기능 사용 예시
- ML01 Clusters (군집분석) 기능 사용 예시
- ML03 Sentiment Analysis (감성분석) 기능 사용 예시
1. ML02 Outliers (이상치) 기능 사용 예시
모집단 데이터를 대상으로 한 분석결과에 대한 신뢰도를 높이기 위해, 모집단 데이터에서 Outliers (이상치) 데이터를 제외한 후 분석을 진행하는 과정이 필요합니다.
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
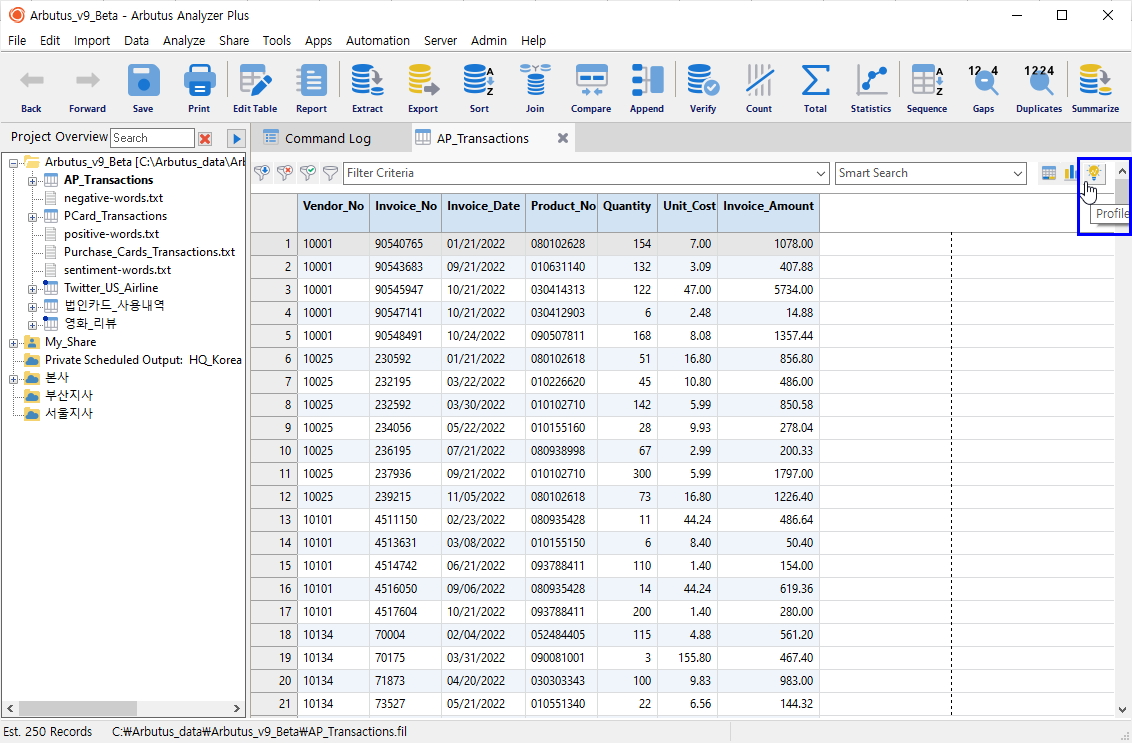
대상 테이블(AP_Transactions)에 대한 데이터 윤곽을 검토해 봅니다.
- View 화면에서 우측 상단 Profile 버튼 클릭
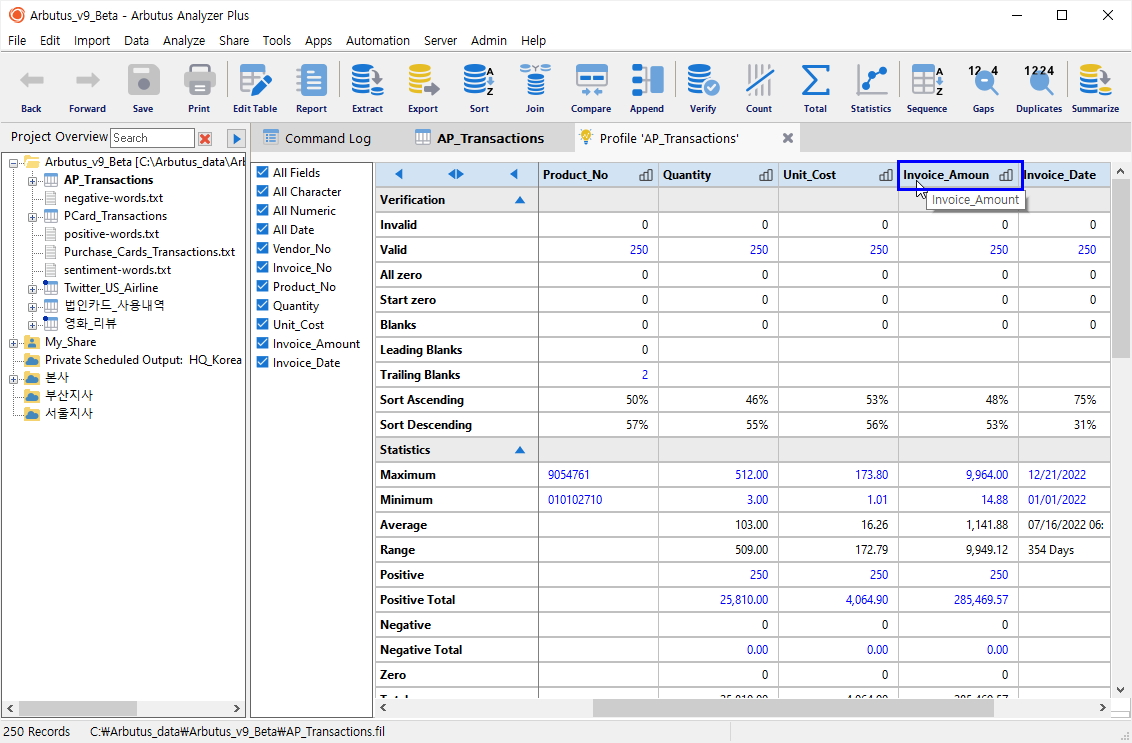
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
Profile 명령은 위와 같이 기본적인 통계수식이 자동으로 반영되어 나타납니다.
- 상단 필드명 중 Invoice_Amount 를 클릭(선택)
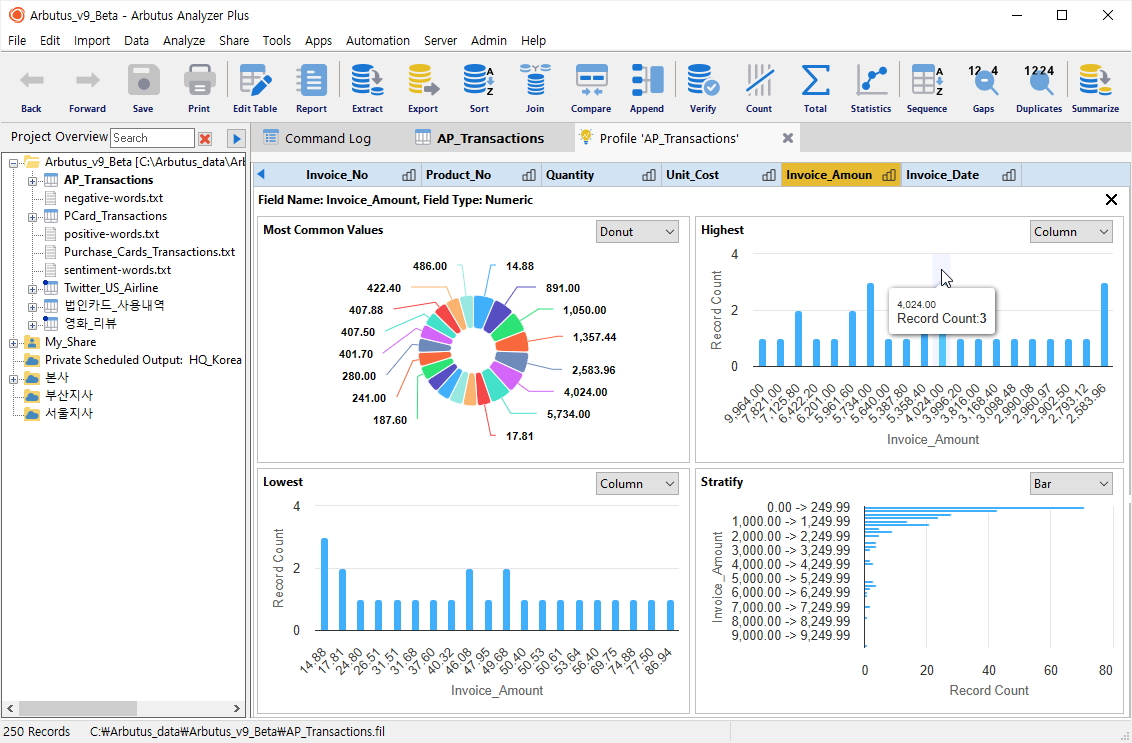
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
전반적인 윤곽 즉, Highest(상위), Lowest(하위), Stratify(계층분석) 값들을 시각적으로 확인해 볼 수 있으며, 마우스가 가리키는 선택 값들을 클릭하면, 필터링 된 해당 데이터들을 확인할 수 있습니다.
아래 절차를 통해서, 확인된 Outliers(이상치) 데이터를 제외해 봅니다.
상단 메뉴 > Apps > AI-ML > ML02 Outliers 클릭
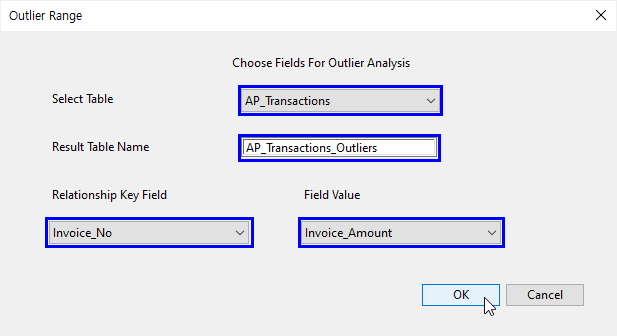
- Select Table: AP_Transactions 선택
- Result Table Name: AP_Transactions_Outliers 입력
- Relations Key Field: Invoice_No 선택
- Field Value: Invoice_Amount 선택
- OK 클릭
Outliers 명령이 수행되면, Overview 메뉴에 Outliers Results 폴더가 생성되며, 이 폴더 내에 결과 테이블(AP_TRANSACTION_OUTLIERS)이 저장됩니다.
결과 테이블에는 아래와 같이 outlier 필드에 정상적인 범위를 벗어난 값 즉, Outlier 값들은 True 로 정상적인 범위 내에 있는 값들은 False 로 표시됩니다.
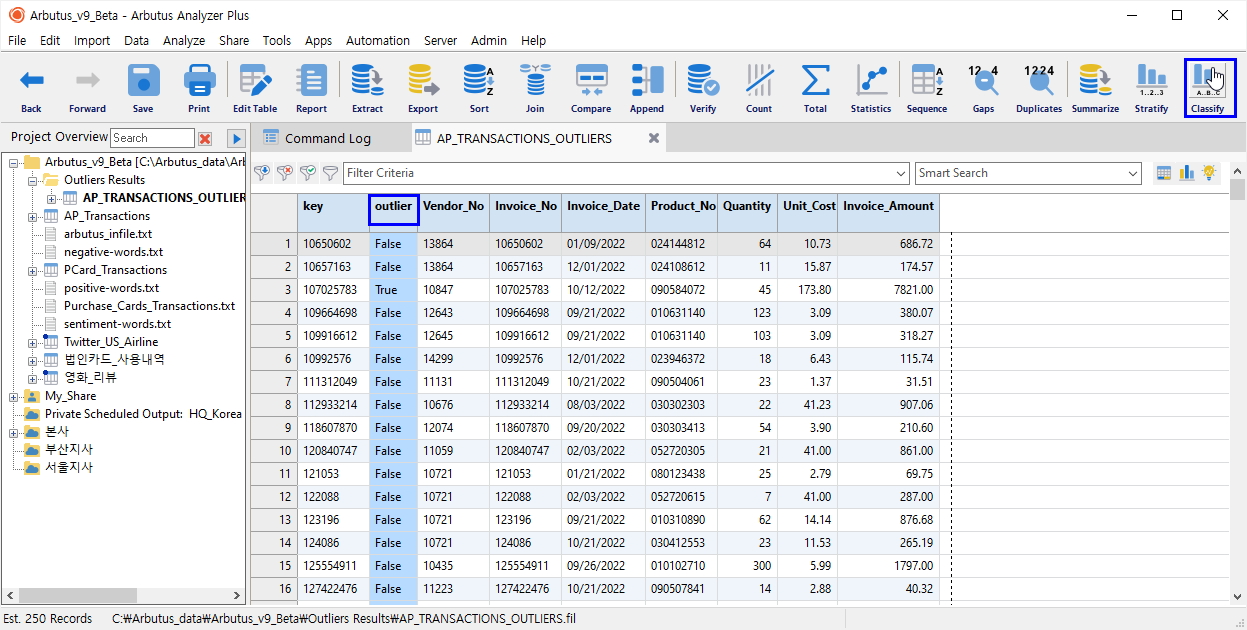
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
전체적인 데이터 분포 확인을 위해
- outlier 필드명 클릭
- 우측 상단 Classify 버튼 클릭
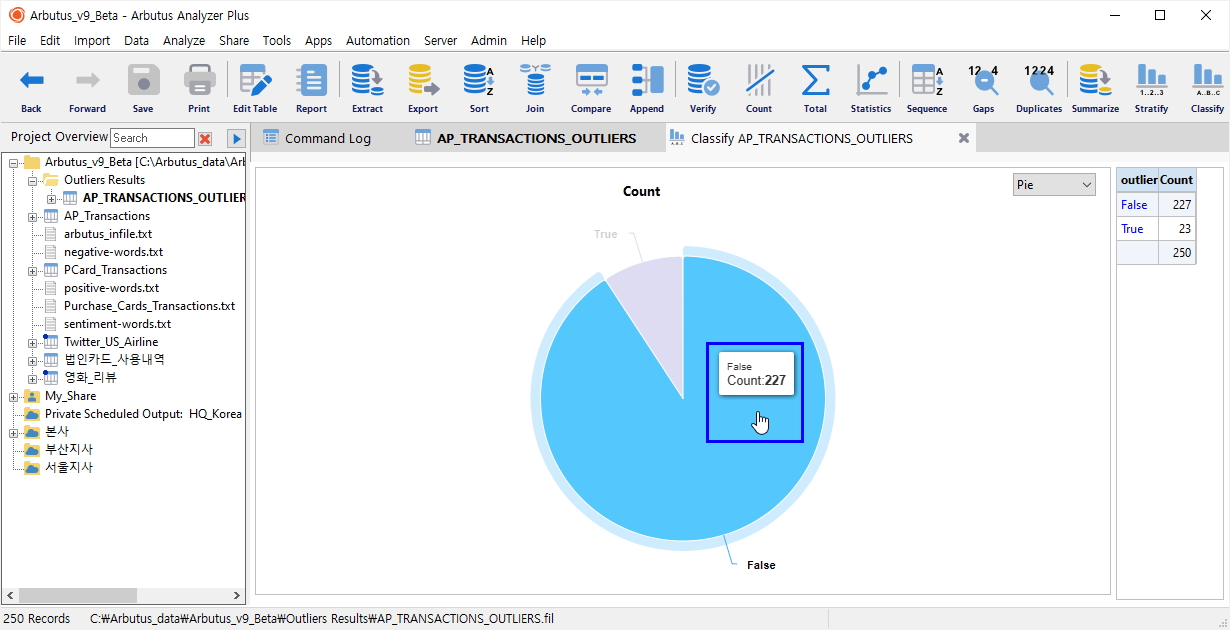
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
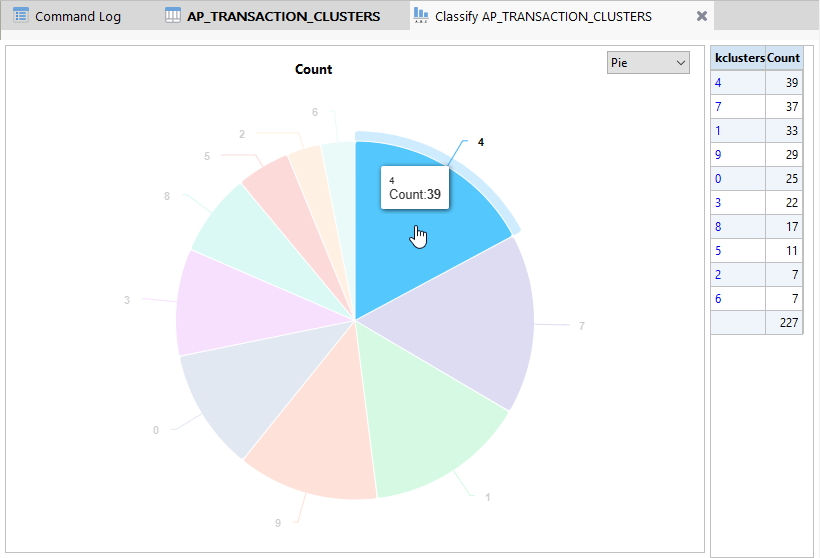
위 화면 우측 표에 outlier False 는 227건, True 는 23건이라고 나타납니다.
위 차트 화면에서 False 즉, Outliers (이상치) 데이터가 아닌 영역에 마우스를 올려 놓으면 227건의 데이터가 표시되며 마우스 클릭을 해봅니다.
아래 View 화면과 같이 False 값만 필터링 된 테이블을 확인할 수 있으며, 이 테이블만 따로 Extract(추출)해 봅니다.
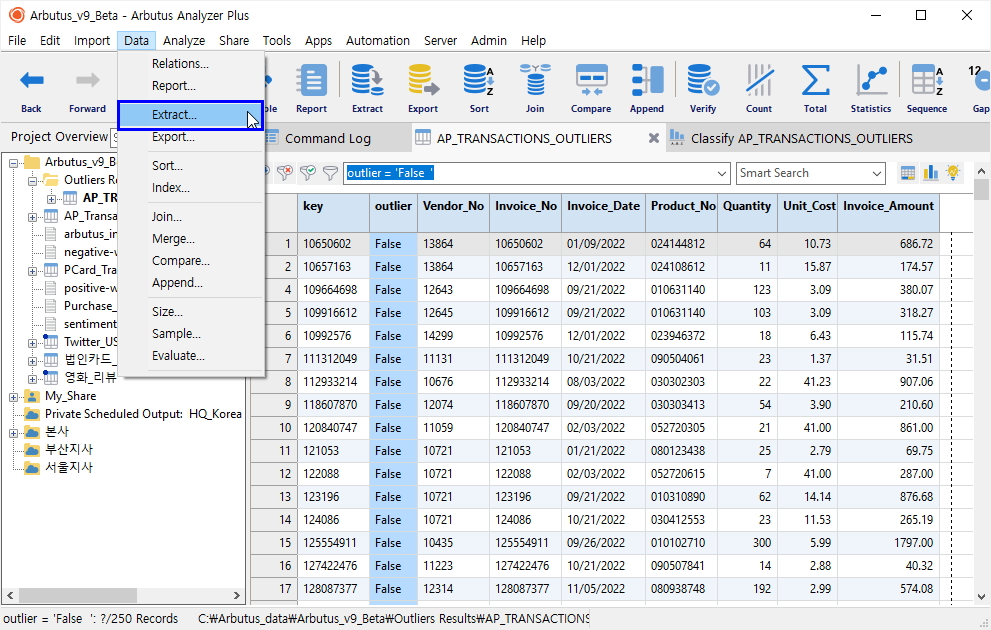
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- 상단 메뉴 Data > Extract 클릭
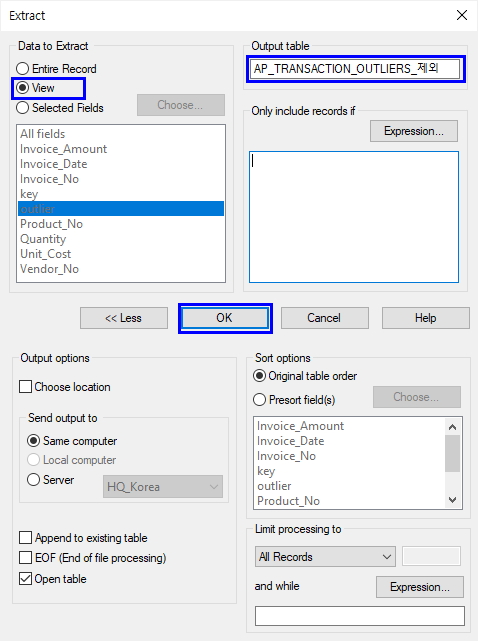
- Data to Extract: View 선택
- Output table: AP_TRANSACTION_OUTLIERS_제외 입력(저장할 테이블 명)
- OK 클릭
아래 View 화면에서와 같이 "AP_TRANSACTION_OUTLIERS_제외" 라는 이름의 테이블이 생성되었습니다.
이 테이블을 대상으로 Visualization(시각화) 버튼 클릭을 통해 전반적으로 데이터를 검토해 봅니다.
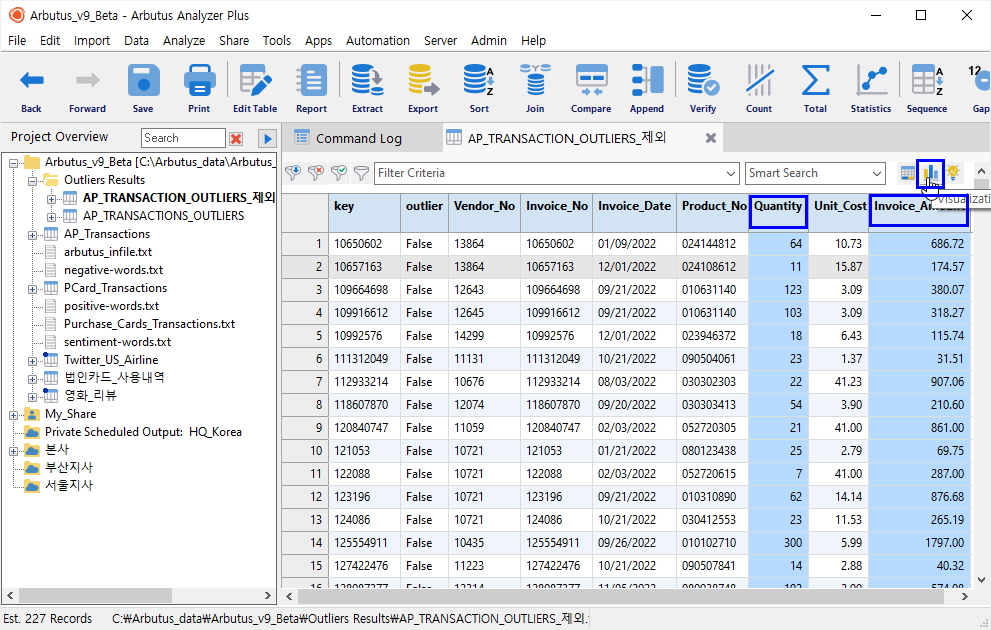
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- 키보드 Crtl 키를 누른 상태에서 Quantify 필드명 클릭 & Invoice_Amount 필드명 클릭
(Quantify 필드와 Invoice_Amount 필드가 선택됨)
- 우측 상단 Visualization(시각화) 버튼 클릭
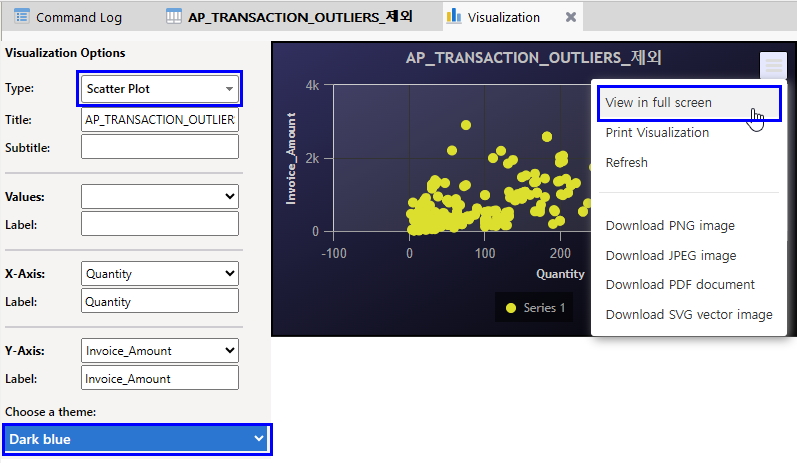
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- Type: Scatter Plot 선택
- Choose a theme: Dark blue 선택 (데이터 성격에 맞는 theme 선택)
- 우측 메뉴 바 클릭 > View in full screen 선택 (full 화면으로 크게 보기)
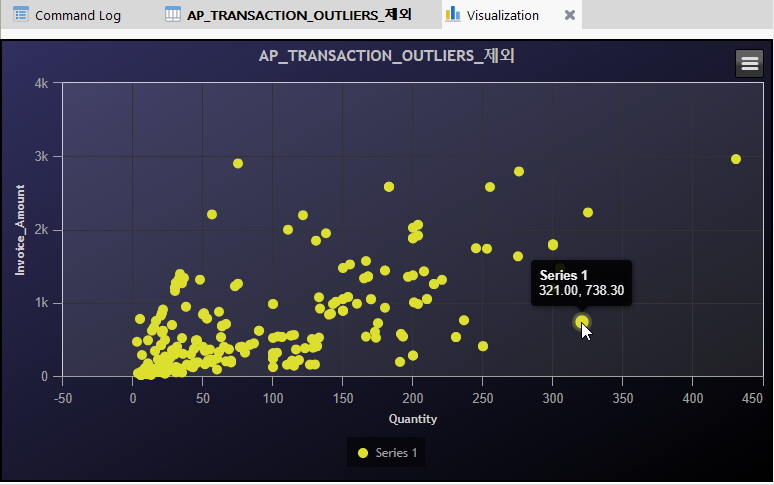
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
위 화면에서 마우스를 옮겨가며 분포현황 및 건수 등을 살펴봅니다.
다시 "AP_TRANSACTION_OUTLIERS_제외" View 화면에서
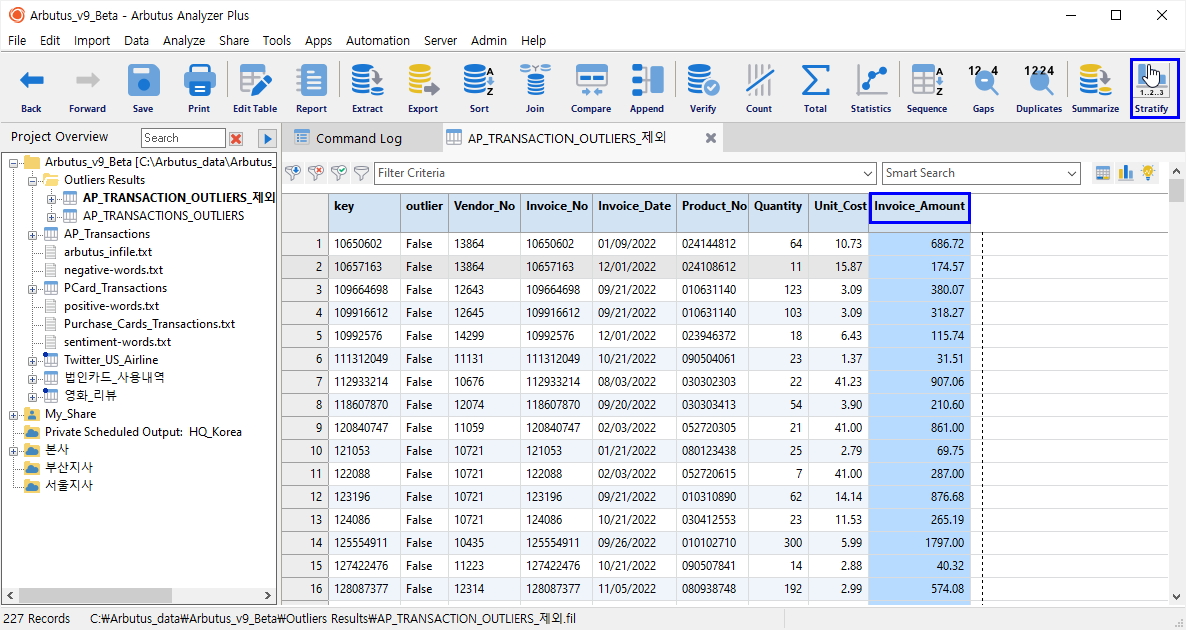
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- Invoice_Amount 필드 선택
- 우측 상단 Stratify(계층분석) 버튼 클릭
아래와 같이 Stratify(계층분석) 결과를 살펴볼 수 있습니다.
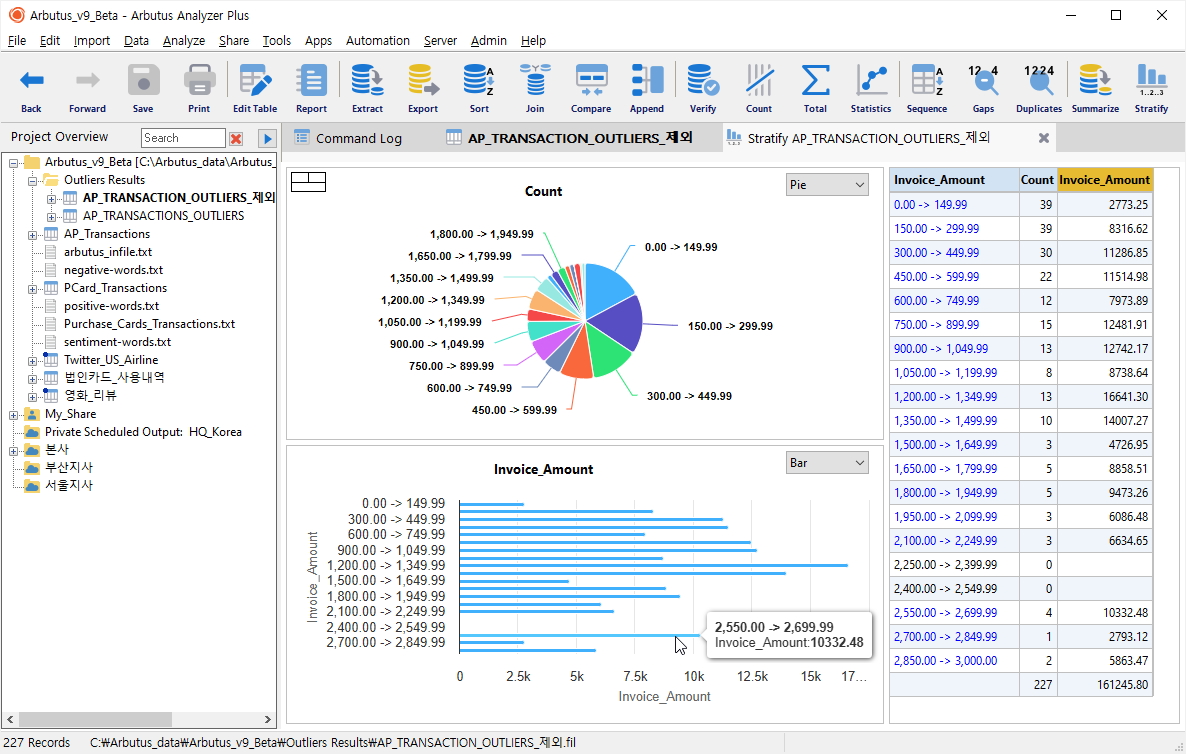
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
2. ML01 Clusters (군집분석) 기능 사용 예시
아래와 같이 선택한 테이블(AP_TRANSACTION_OUTLIERS_제외)을 대상으로 Clusters (군집) 분석을 진행해 봅니다.
** 앞서 "AP_TRANSACTION_OUTLIERS_제외" 테이블은 분석결과의 신뢰도를 위해 Outliers(이상치) 데이터를 제외한 것입니다.
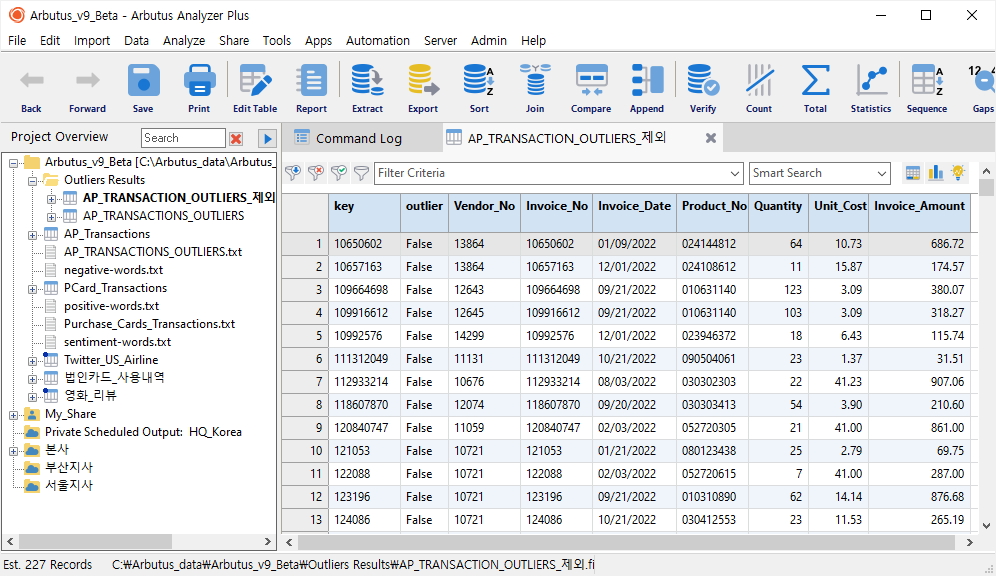
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
상단 메뉴 > Apps > AI-ML > ML01 Clusters 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- Select Table: AP_TRANSACTION_OUTLIERS_제외 선택
- Result Table Name: AP_TRANSACTION_CLUSTERS 입력
- Relations Key Field: Invoice_No 선택
- Number of Clusters: 10 입력 (10개 군집으로 분석하고자 할 때)
- Numeric Field1: Invoice_Amount 선택
- Numeric Field2: Quantity 선택
- OK 클릭
Clusters 명령이 수행되면, Overview 메뉴에 Clusters Results 폴더가 생성되며, 이 폴더 내에 결과 테이블(AP_TRANSACTION_CLUSTERS)이 저장됩니다.
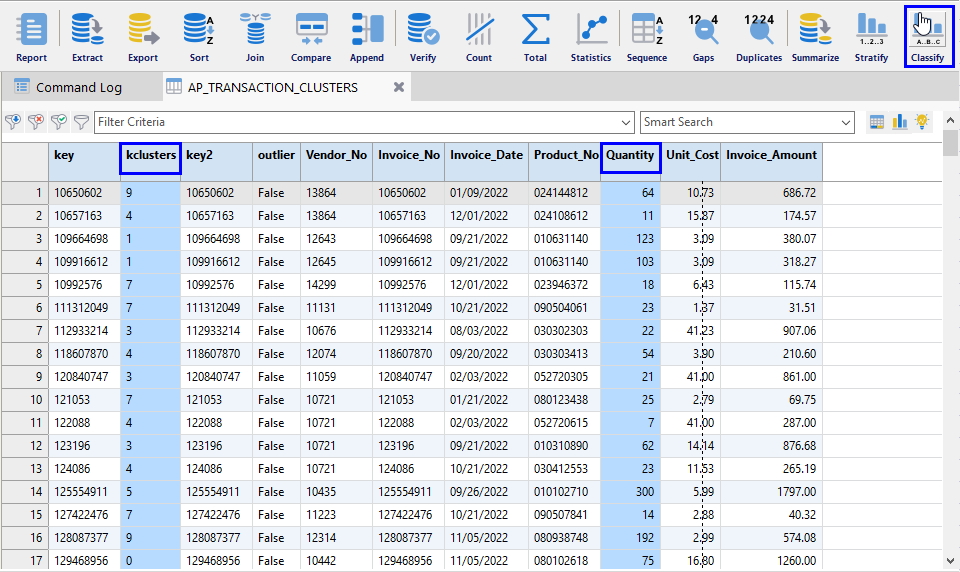
결과 테이블에는 아래와 같이 kclusters 필드에 각각의 해당 군집(앞서 10개의 군집으로 분석 진행)이 표시됩니다.
아래 화면에서와 같이 Clusters(군집) 분석 결과 테이블 "AP_TRANSACTION_CLUSTERS"의 kclusters 필드를 대상으로 검토를 위해 Classify(분류) 명령을 실행해 봅니다.
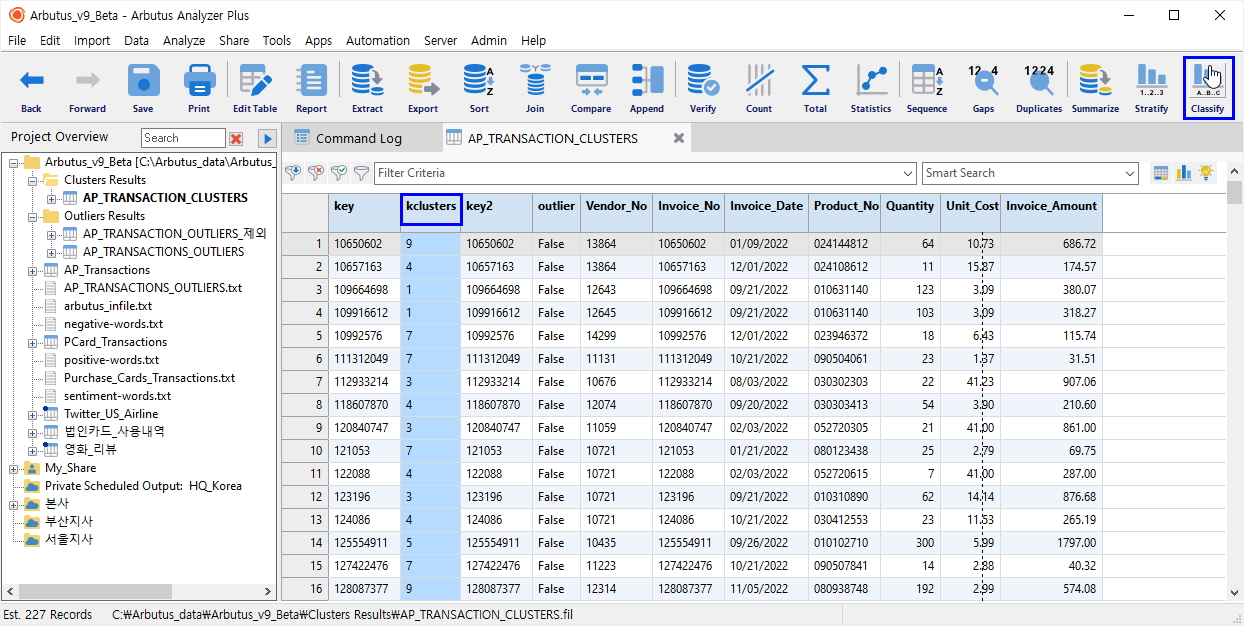
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- kclusters 필드 선택
- 우측 상단 Classify(분류) 버튼 클릭
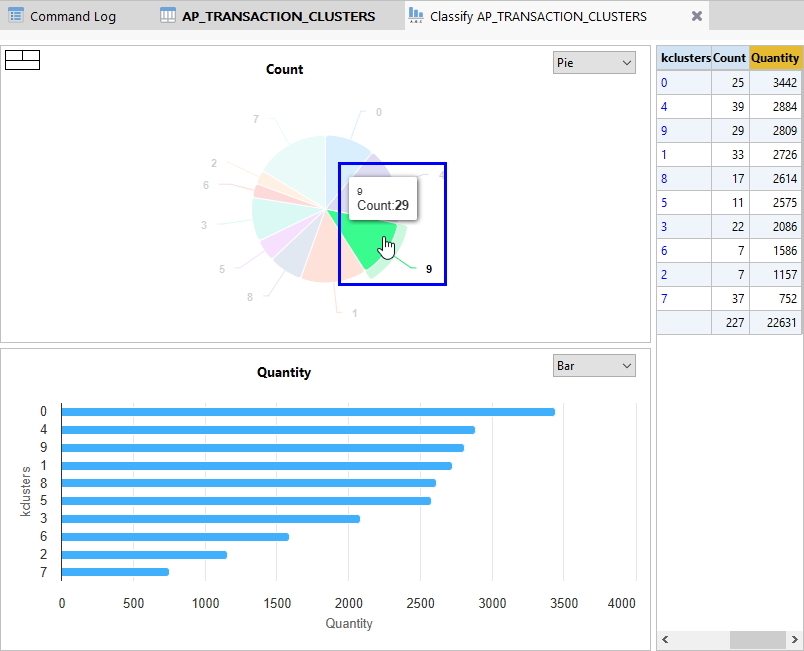
아래 화면에서와 같이 각 kclusters(군집) 별 Count 개수 및 분포를 확인해 볼 수 있습니다.
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
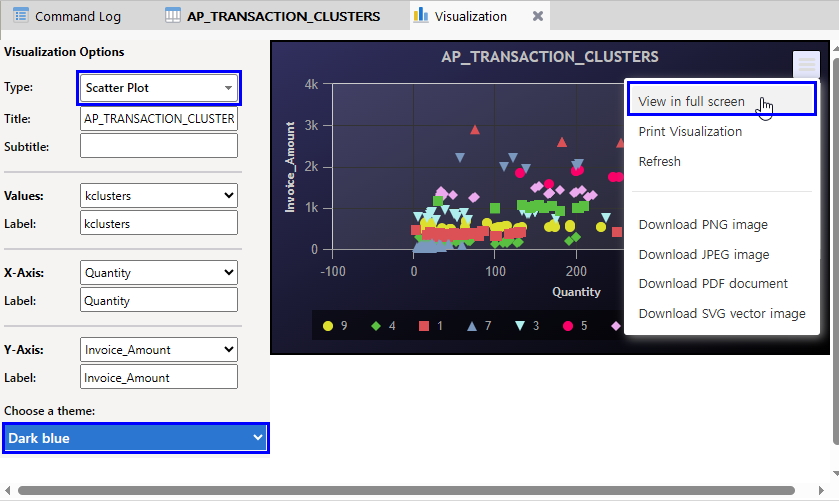
다시 이 테이블을 대상으로 Visualization(시각화) 버튼 클릭을 통해 전반적으로 데이터를 검토해 봅니다.
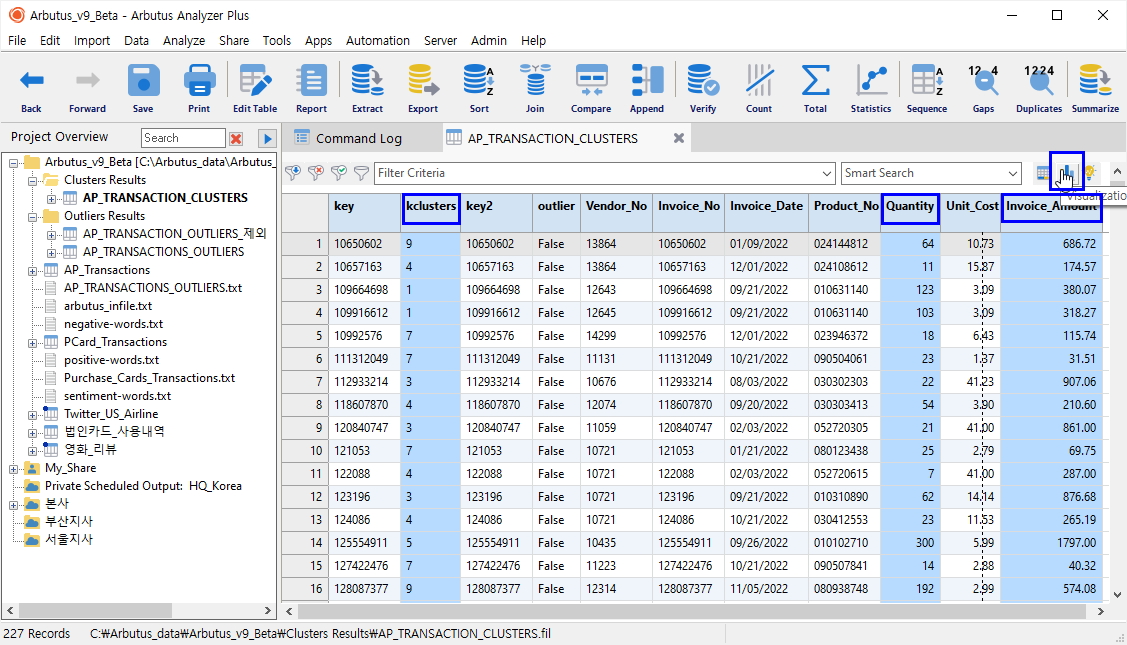
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- 키보드 Crtl 키를 누른 상태에서 kclusters 필드명 클릭 & Quantity 필드명 클릭 & Invoice_Amount 필드명 클릭
(kclusters 필드, Quantity 필드, Invoice_Amount 필드가 선택됨)
- 우측 상단 Visualization(시각화) 버튼 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- Type: Scatter Plot 선택
- Choose a theme: Dark blue 선택 (데이터 성격에 맞는 theme 선택)
- 우측 메뉴 바 클릭 > View in full screen 선택 (full 화면으로 크게 보기)
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
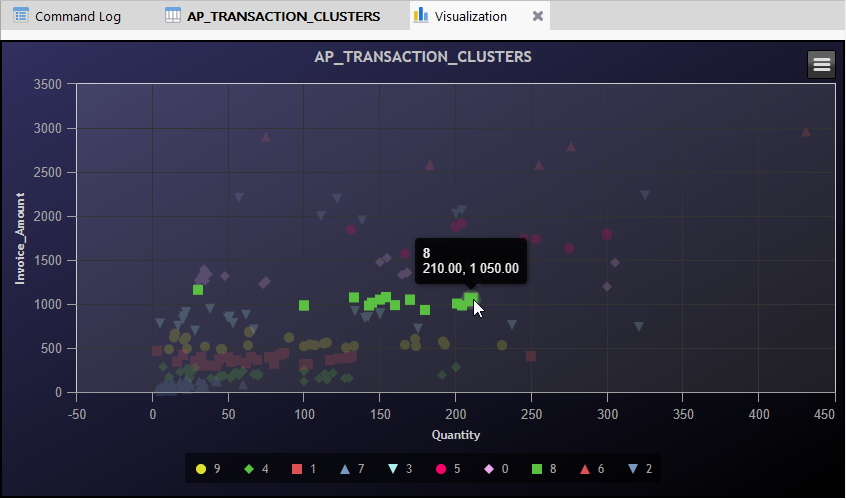
위 화면에서와 같이 각 군집별 구분(10개) 분포현황 및 건수 등에 대해서 마우스를 옮겨가며 살펴봅니다.
이어서 아래 화면과 같이 kclusters (군집) 필드와 Quantity 필드를 대상으로 Classify(분류) 명령을 실행해 봅니다.
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
좀 더 자세한 데이터 분포 확인을 위해
- 키보드 Crtl 키를 누른 상태에서 kclusters 필드명 클릭 & Quantity 필드명 클릭
(kclusters 필드와 Quantity 필드가 선택됨)
- 우측 상단 Classify 버튼 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
위 화면 우측 표에 Classify(분류) 명령 실행 결과가 나타납니다.
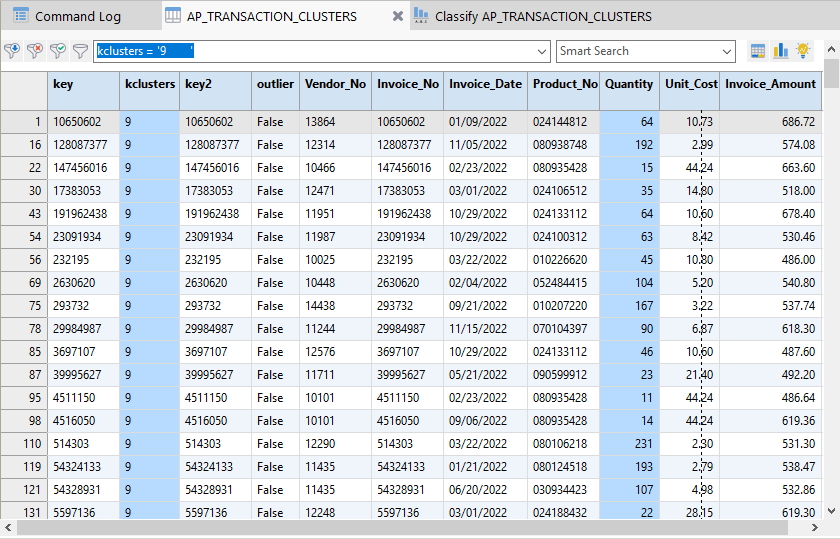
또한 차트 화면에서 각 영역에 마우스를 이동해 가며 Count 및 Quantity 를 확인하고, 해당 건(군집)의 데이터가 표시된 곳을 마우스 클릭하면 필터링 된 데이터를 아래와 같이 확인해 볼 수 있습니다.
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
3. ML03 Sentiment Analysis (감성분석) 기능 사용 예시
아래 화면과 같이 리뷰 데이터인 text 필드를 대상으로 Sentiment Analysis(감성분석)를 진행해 봅니다.
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
상단 메뉴 > Apps > AI-ML > ML03 Sentiment Analysis 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
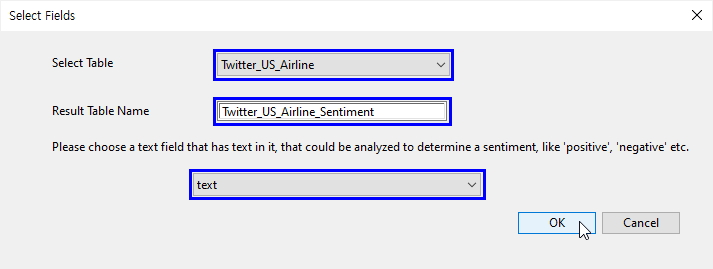
- Select Table: Twitter_US_Airline 선택
- Result Table Name: Twitter_US_Airline_Sentiment 입력
- Please choose a text field ... : text 필드 선택 (감성분석 대상 필드)
- OK 클릭
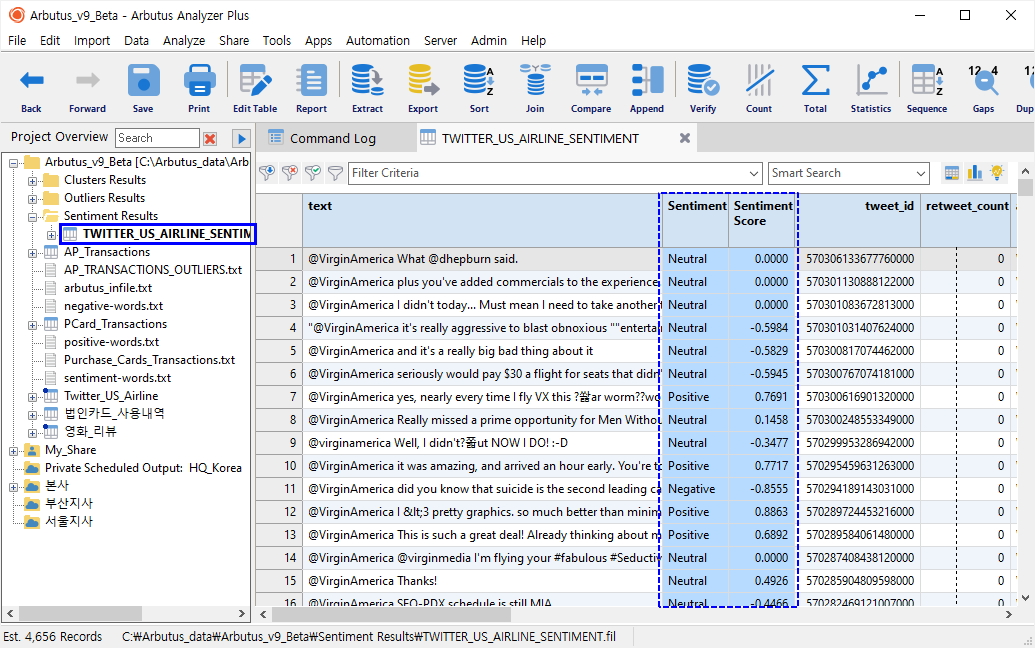
Sentiment Analysis (감성분석) 명령이 수행되면, Overview 메뉴에 Sentiment Results 폴더가 생성되며, 이 폴더 내에 결과 테이블(Twitter_US_Airline_Sentiment)이 저장됩니다.
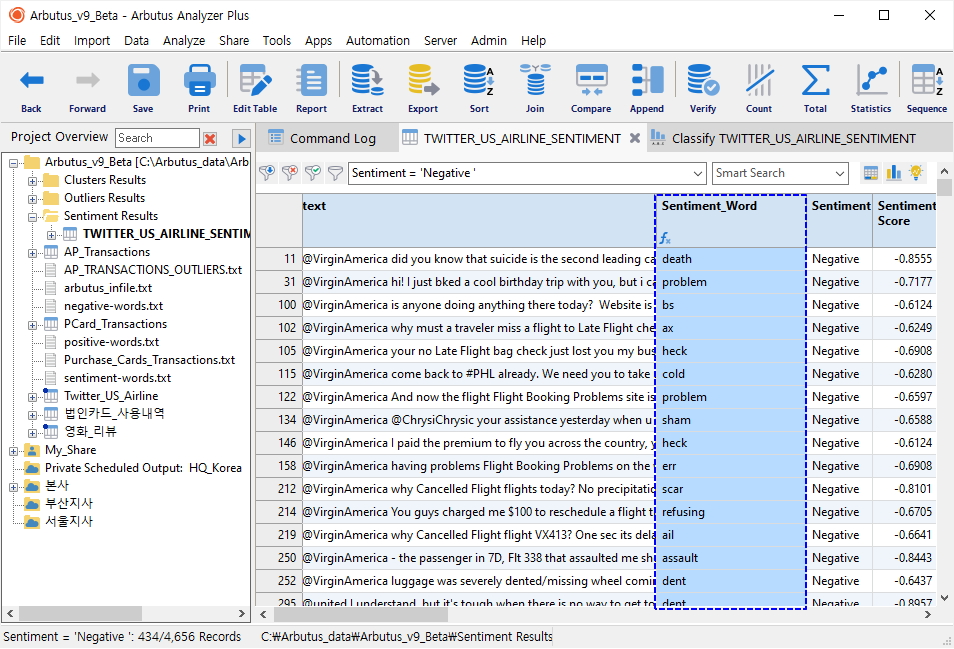
결과 테이블에는 아래와 같이 Sentiment 및 Sentiment Score 필드에 각각의 분석된 값이 표시됩니다.
- Sentiment 필드: Neutral(중립), Negative(부정), Positive(긍정) 값 표시
- Sentiment Score 필드: 각각의 Score 값 표시
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
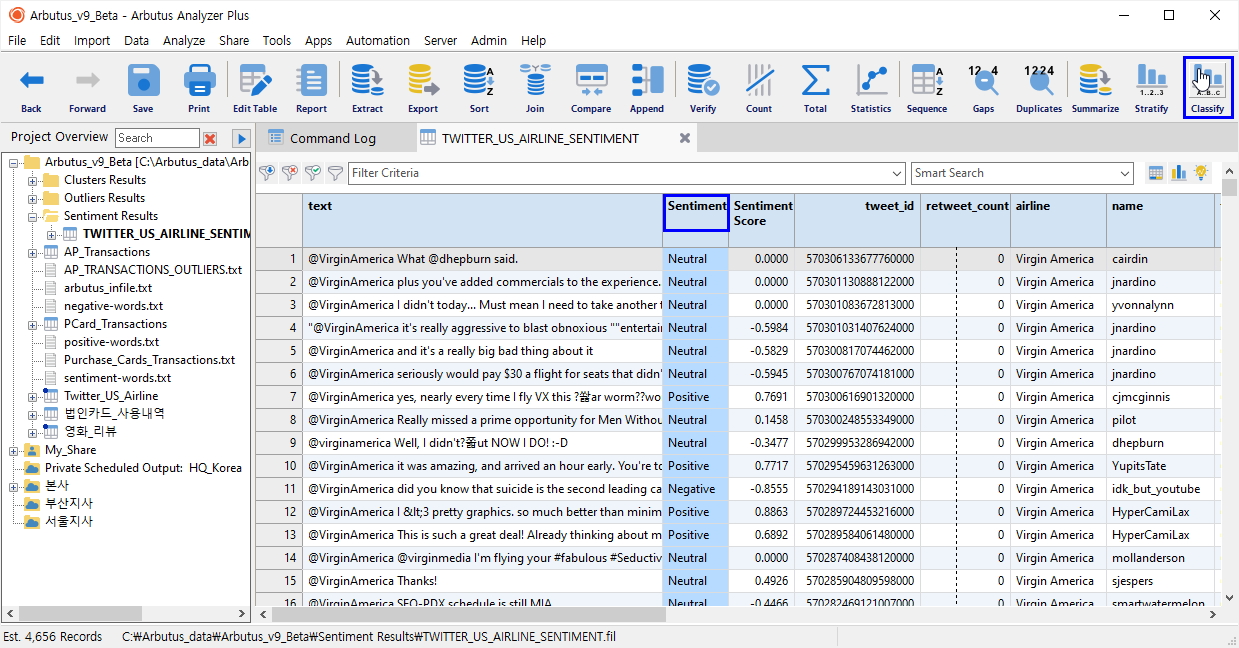
아래 화면에서와 같이 Sentiment Analysis (감성분석) 결과 테이블 "TWITTER_US_AIRLINE_SENTIMENT"의 Sentiment 필드를 대상으로 검토를 위해 Classify(분류) 명령을 실행해 봅니다.
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- Sentiment 필드 선택
- 우측 상단 Classify(분류) 버튼 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
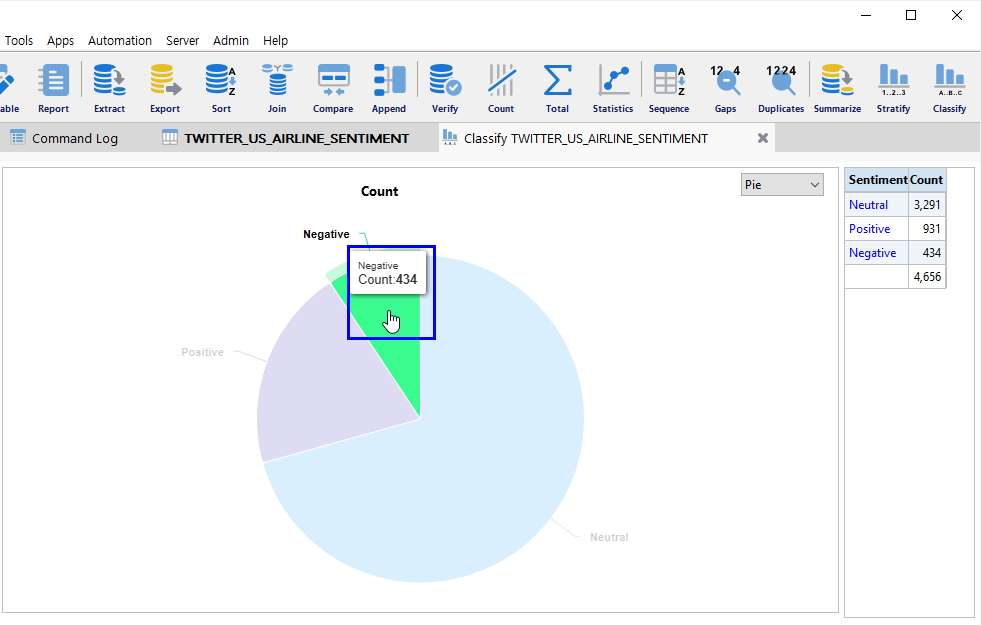
위 화면 우측 표에 Sentiment Analysis (감성분석) 실행 결과가 나타납니다.
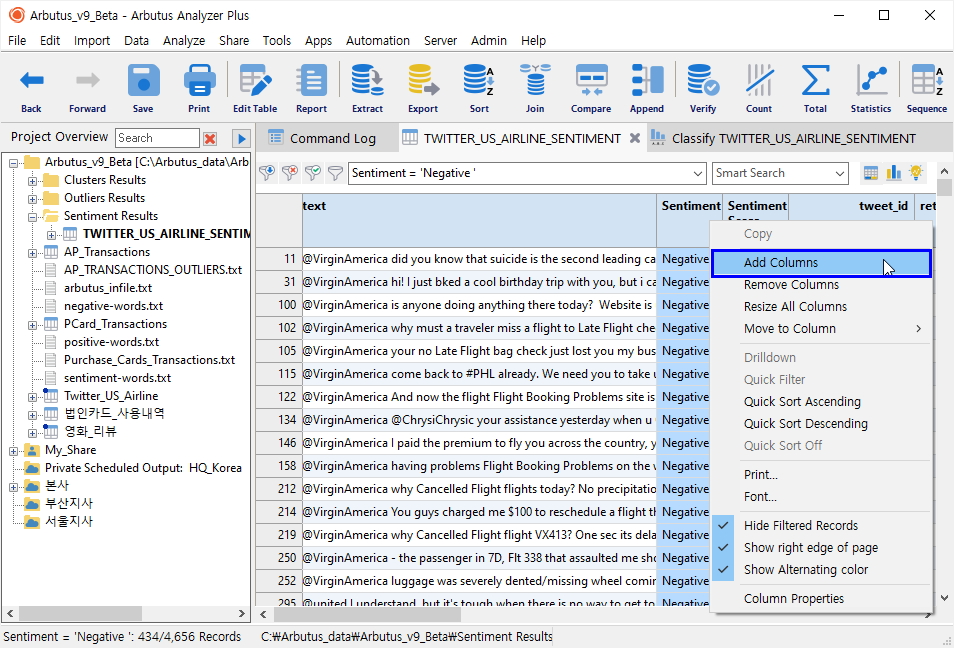
Sentiment(감성) 분류 즉, Neutral(중립), Negative(부정), Positive(긍정) 별 Count 개수를 확인하고, 해당 건의 데이터가 표시된 곳을 마우스 클릭하면 필터링 된 데이터를 아래와 같이 확인해 볼 수 있습니다.
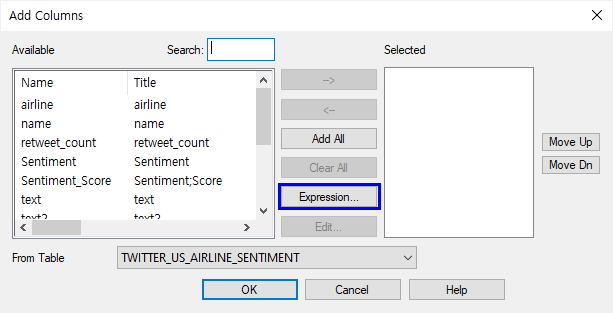
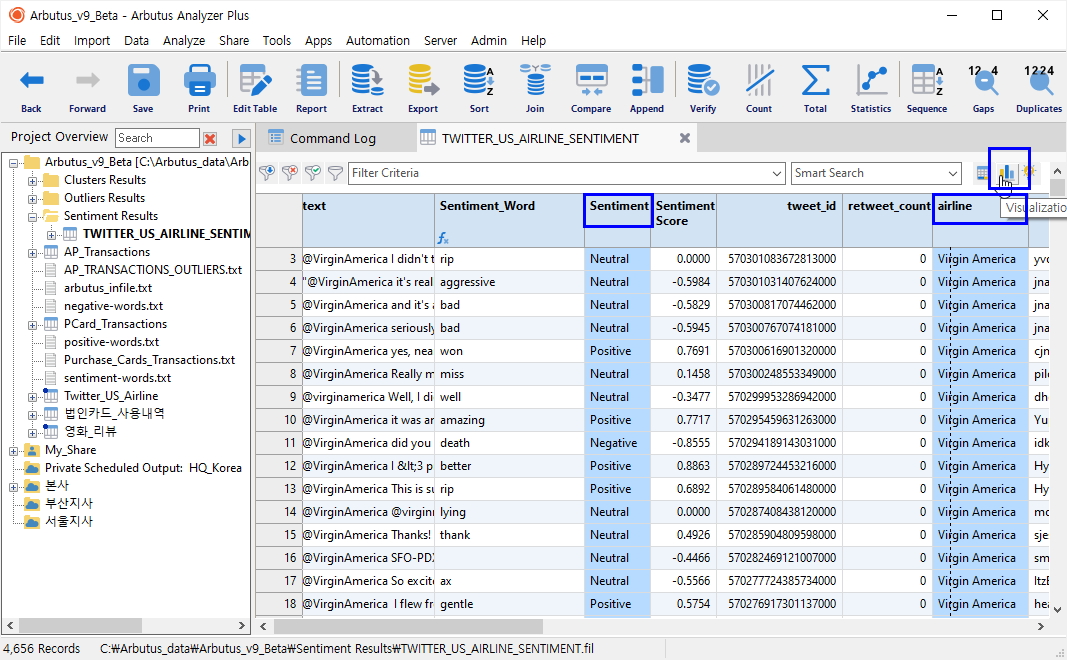
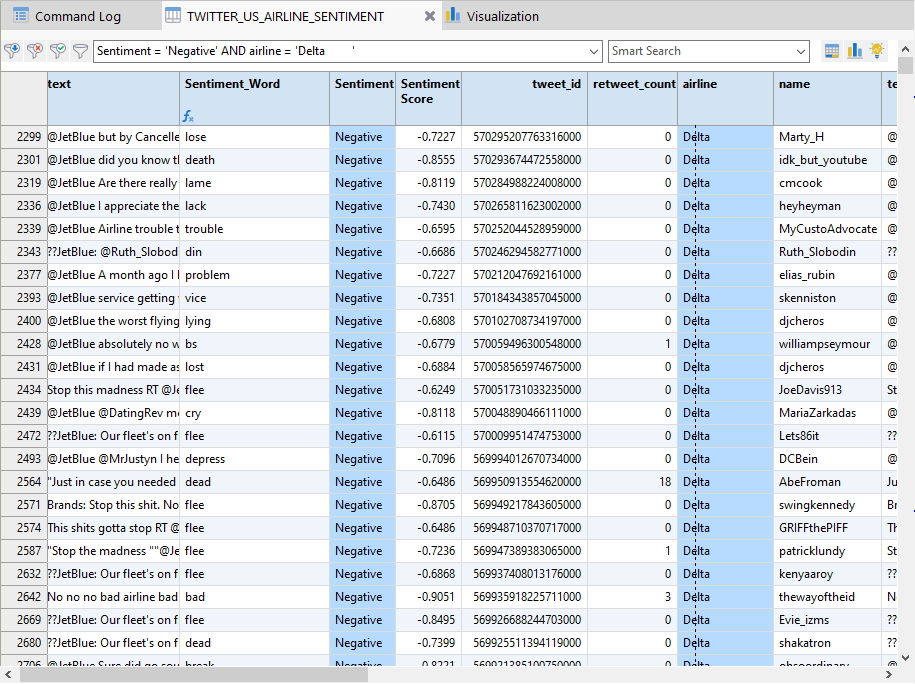
이후 필터링 된 테이블에 감성사전의 어떤 키워드가 매칭되었는지 Expression(표현식)을 적용해서 Add Columns 를 진행해 봅니다.
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- Sentiment 필드명 클릭
(Sentiment 필드 옆에 Add Column 하기 위해)
- 마우스 우 클릭 > Add Columns 메뉴 클릭
아래와 같이 감성사전을 기반으로 어떤 키워드가 매칭이 되었는지 확인해 보기 위해서 위와 같이 계산된 필드를 추가해 봅니다.
- Expression 버튼 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
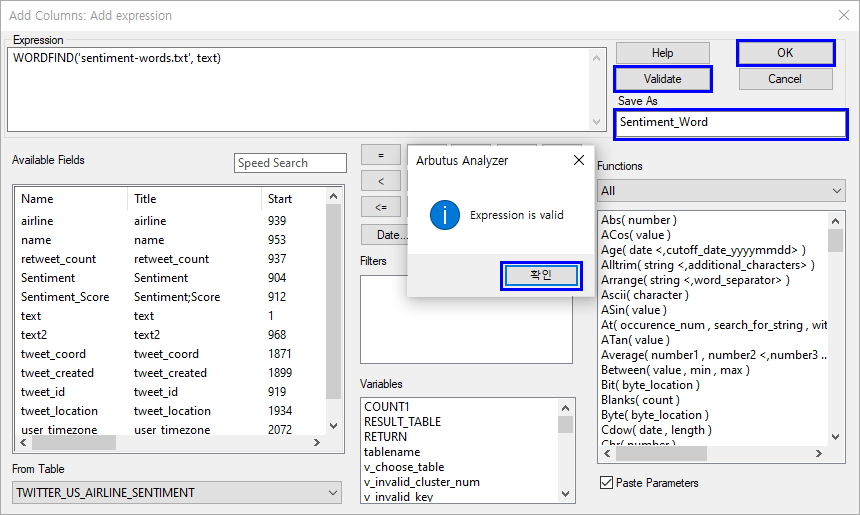
- Expression(표현식)란에 WORDFIND('sentiment-words.txt', text) 입력
** sentiment-words.txt 는 인터넷 검색으로 확보한 감성사전의 positive-words.txt 와 negative-words.txt 를 하나로 합체하여 사용해 보았습니다.
- Save As 란에 필드명 Sentiment_Word 입력
- Validate(유효성) 클릭
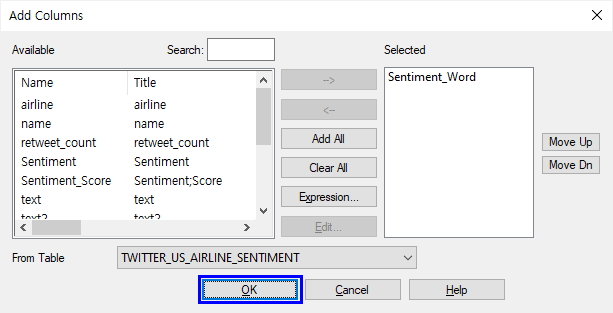
- OK 클릭
- OK 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
위와 같이 추가된 Sentiment_Word 필드란에 매칭된 키워드가 나타납니다.
이후 Visualization(시각화) 검토를 위해 아래와 같이 진행해 봅니다.
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- 앞서 진행했던 필더(Sentiment = 'Negative')를 제거 후 전체 데이터를 대상으로 진행
- 키보드 Crtl 키를 누른 상태에서 Sentiment 필드명 클릭 & airline 필드명 클릭
(Sentiment 필드와 airline 필드가 선택됨)
- 우측 상단 Visualization(시각화) 아이콘 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
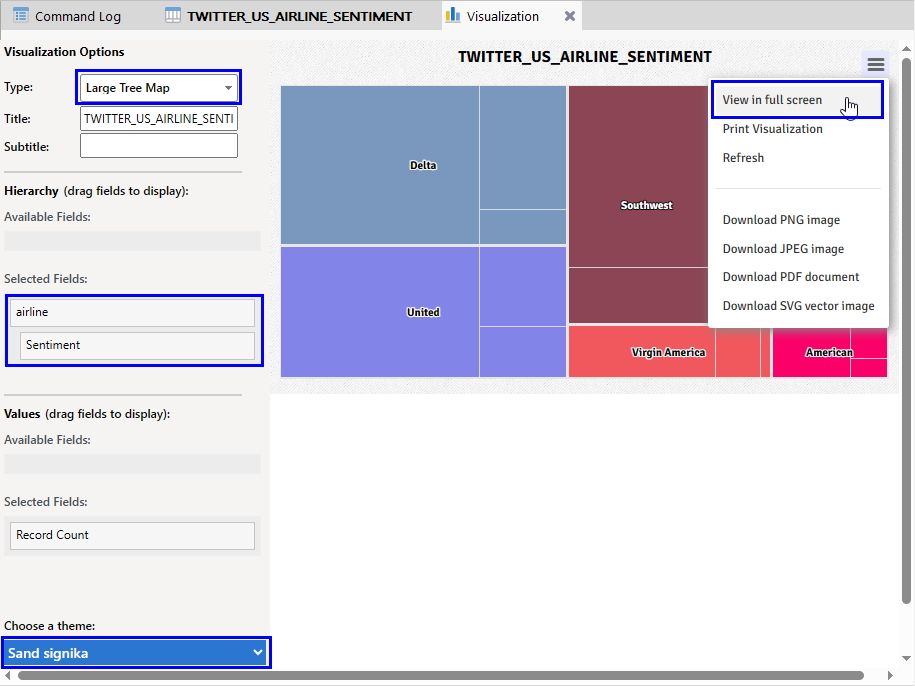
- Type: Large Tree Map 선택
- Selected Fields: airline 및 Sentiment 필드 선택
(마우스로 해당 필드 이름을 드래그하여 위 화면과 같이 배치되도록 이동)
- Choose a theme: Sand signika 선택 (식별을 용이하게 하기 위해 위와 같이)
- 우측 상단 View in full screen 클릭 (화면을 크게 보기 위해)
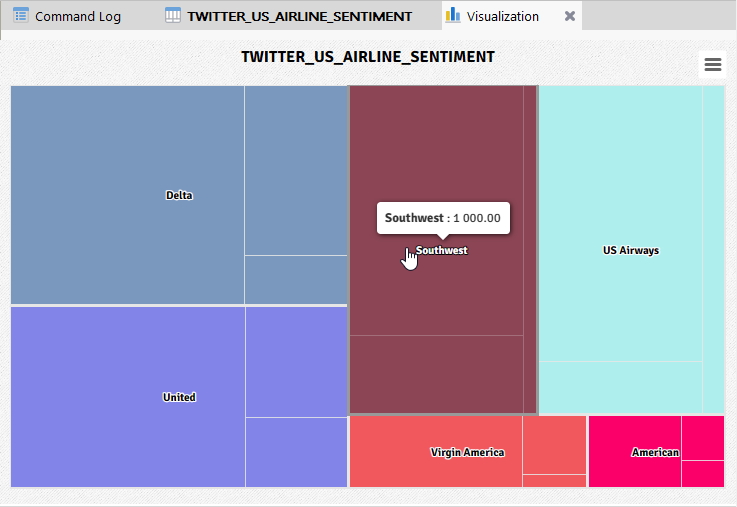
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
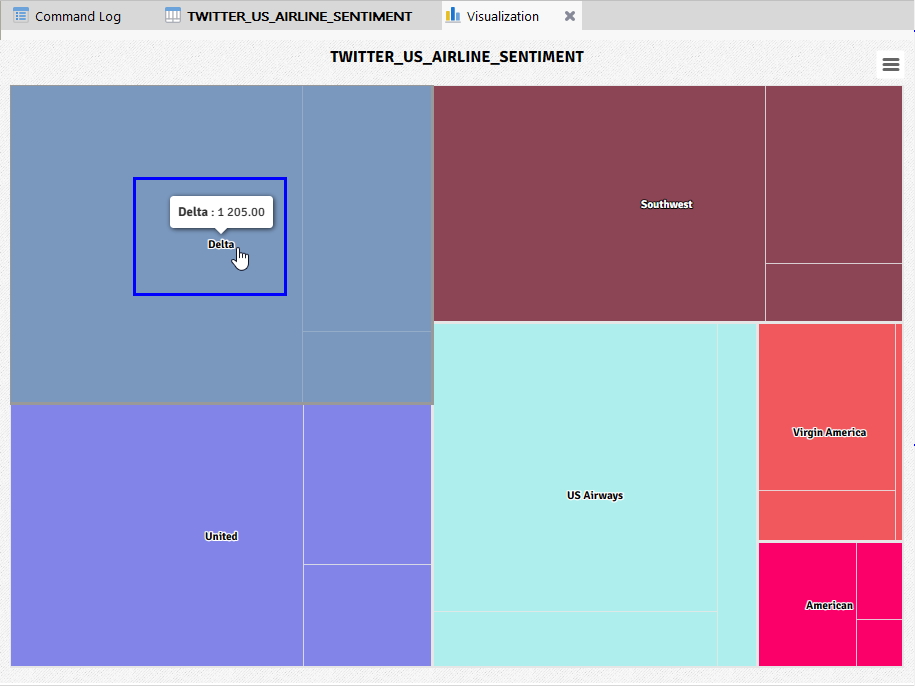
위 Visualization(시각화) 화면에서 각 항공사별 감성분석 현황에 대해 마우스를 옮겨가며 살펴봅니다.
- Delta 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
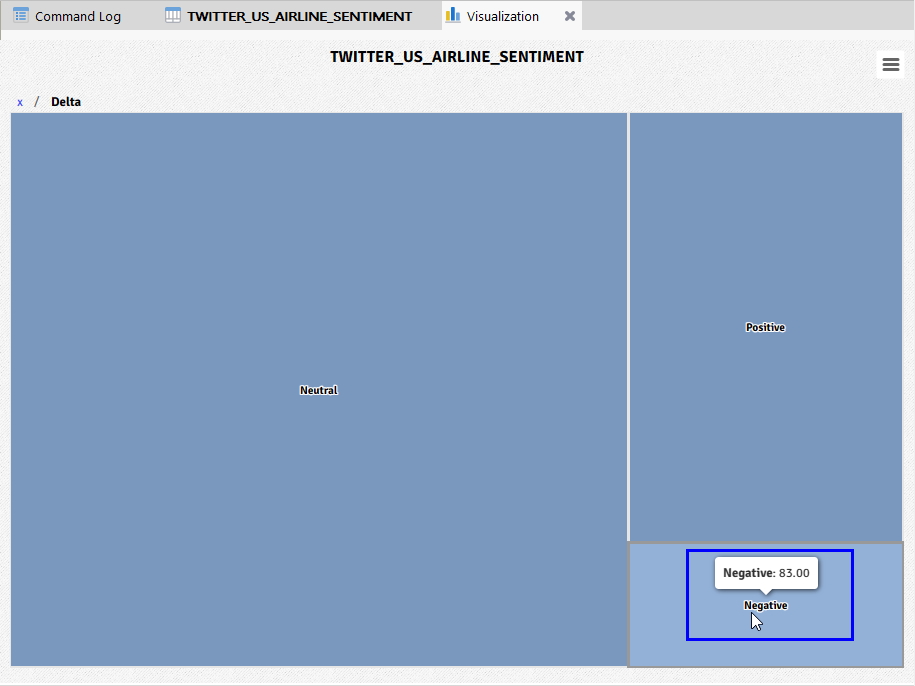
위와 같이 Delta 항공에 대한 Positive(긍정), Negative(부정), Neutral(중립) 별로 구분된 데이터를 확인할 수 있습니다.
- Negative(부정) 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
위 화면과 같이 Delta 항공을 대상으로 Sentiment 필드 중 Negative(부정)에 대한 데이터만 필터링 된 것을 확인할 수 있습니다.
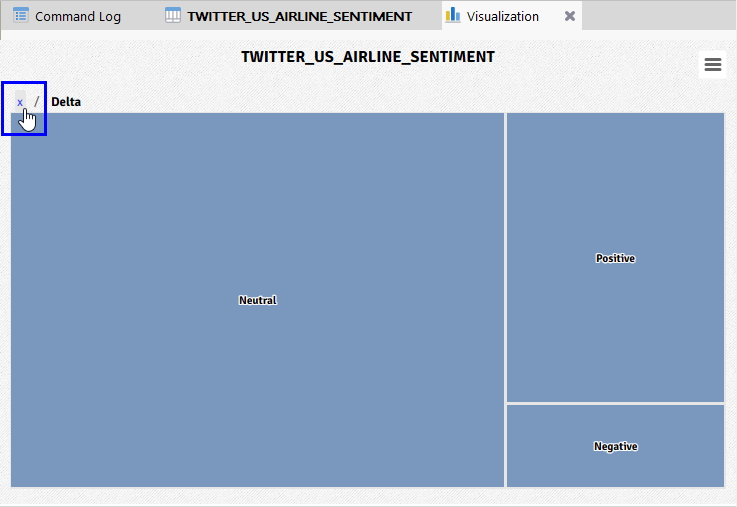
다른 항공사를 대상으로 살펴 보려면, 아래 화면과 같이
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
- 닫기(X) 아이콘을 클릭한 후
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
다른 항공사를 선택하여 앞선 방법과 동일하게 필터링해 봅니다.
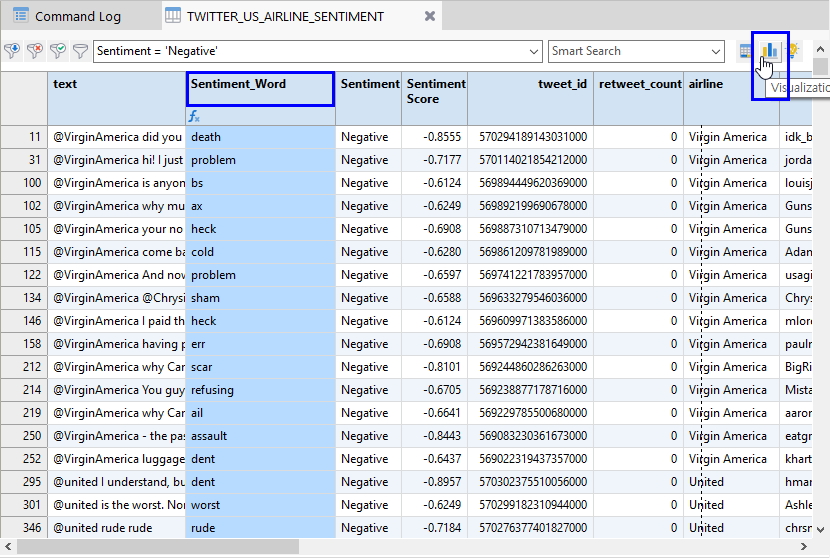
아래 화면과 같이 Negative(부정)에 해당하는 필터링 된 데이터만을 대상으로 앞서 추가했던 Expression(표현식) 필드인 Sentiment_Word 에 대해 Visualization(시각화) 실행 시 차트 Word Cloud 를 선택하여 진행해 봅니다.
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
Visualization(시각화) 검토를 위해
- Sentiment_Word 필드명 클릭
- 우측 상단 Visualization(시각화) 아이콘 클릭
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
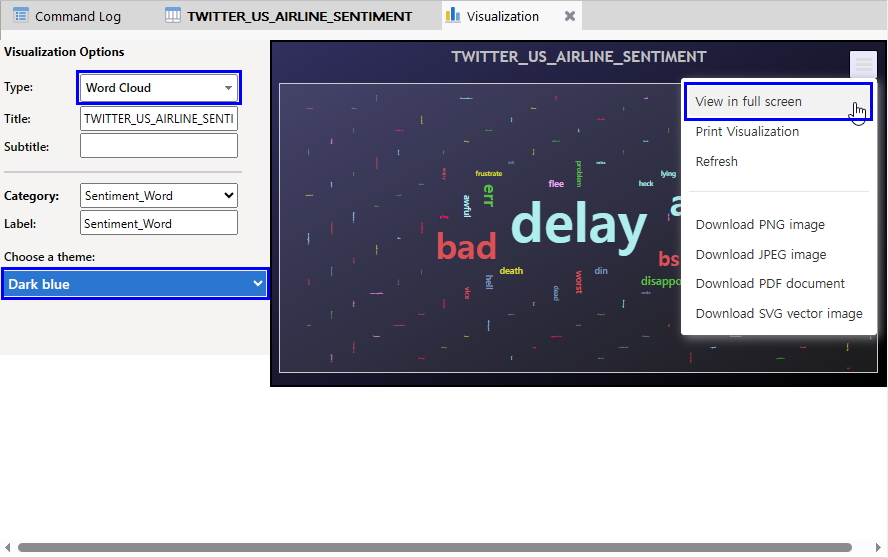
- Type: Word Cloud 선택
- Choose a theme: Dark blue 선택 (데이터 성격에 맞는 theme 선택)
- 우측 메뉴 바 클릭 > View in full screen 선택 (full 화면으로 크게 보기)
(※ 위 이미지를 클릭하면, 더 큰 화면으로 볼 수 있습니다.)
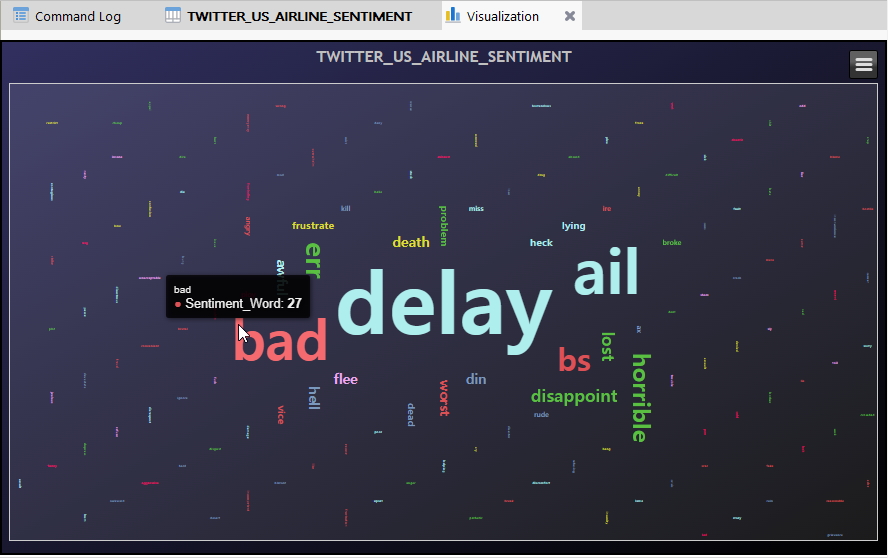
위 화면에서와 같이 Negative(부정)에 속하는 각 단어(키워드)들의 분포현황 및 건수 등에 대해서 마우스를 옮겨가며 살펴봅니다.