

[기술적 해법(Technical Insights) | Data Quality Management Practical Tests and Scripted Solutions]
원문 출처: https://www.arbutussoftware.com/en/technical-insights/data-quality-management
데이터 품질(Data's quality)을 테스트하기 위해 수행할 수 있는 몇 가지 간단한 단계가 있습니다.
이상적으로는, Arbutus Analyzer 에서 파일을 정의(defining a file)한 직후와 분석을 시작하기 전에 이 작업을 수행해야 합니다.
아래 테스트를 실행하면 결과(result)가 Command Log(명령 로그)에 기록됩니다.
Script 를 사용하여 테스트를 실행하고, script 가 결과(result)를 output file(출력 파일)로 보내도록 하는 것이 가장 좋습니다.
이것은 테스트가 수행되었음을 입증하기 위한 작업 문서(workpapers)의 일부가 될 수 있습니다.
데이터 품질 관리(Data Quality) 실전 테스트 및 Script 솔루션
[1단계 테스트]
제어 합계(Control Totals):
데이터 공급자에게 소스 데이터에 있는 레코드(record) 수와 숫자 필드(numeric field)에 대한 제어 또는 해시 합계(control or hash totals)를 알려달라고 요청합니다.
** Control Total: 파일이나 레코드 중에서 공통 항목을 포함한 필드의 합계. 입력 데이터 신뢰도나 프로그램 처리 등의 검사에 사용.
** Hash Total: 오류 검출을 목적으로 컴퓨터 시스템에서 처리되는 데이터 항목들의 해시값을 모두 합산한 값. 데이터 처리 후에 데이터의 값들을 다시 계산하고 해시 합계와 비교하여 오류 발생을 검출할 수 있다.
- 레코드 수(Record count)를 문서화하는 Count command
- 제어/해시 합계(Control/Hash Totals)의 key numeric field(숫자 필드)에 대한 Total command
레코드의 고유성(Uniqueness of Records)
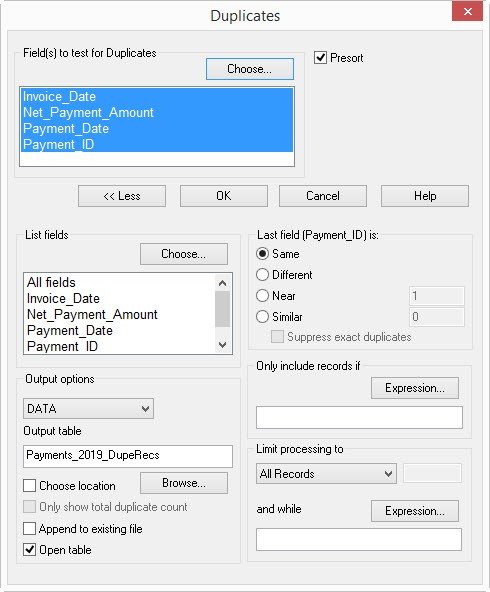
데이터가 처리되면서 여러 가지 방식으로 손상될 수 있습니다.
데이터베이스에서 추출(extraction)을 수행하고, 파일을 압축(zipping up)하거나, 전자 메일(e-mail) 첨부 파일로 보내는 것도 손상(corruption)을 유발할 수 있는 활동입니다.
숫자(Numeric) 및 날짜(date) 필드는 특히 취약합니다.
- 숫자 필드(Numeric field)에 숫자가 아닌 문자(Non-numeric character)
- 유효하지 않거나 비어 있는 날짜(Invalid/blank date)
- 보이지 않는/인쇄할 수 없는(Invisible/non-printing) 문자(예: 탭-tab 과 같은)
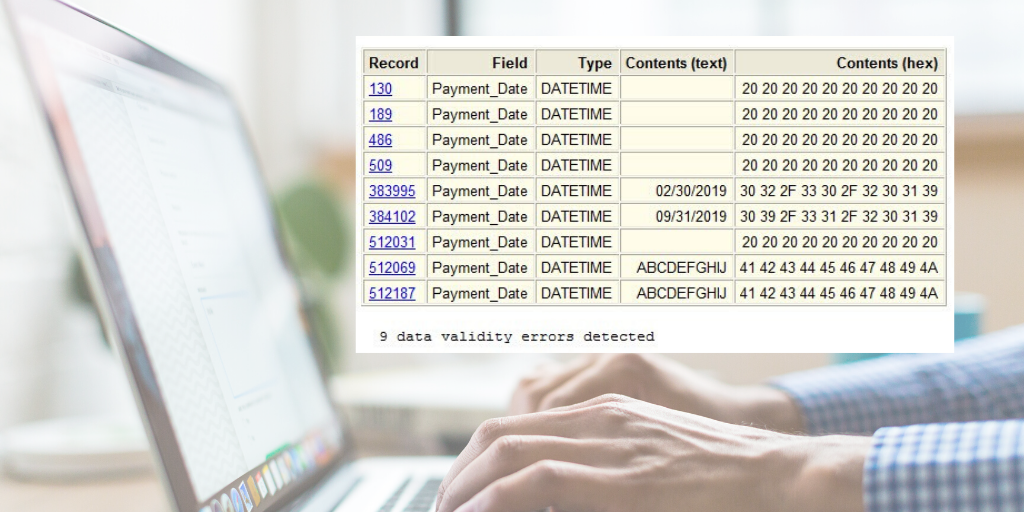
숫자 및 날짜(Numeric & date) 필드가 품질 테스트의 주요 후보입니다.
데이터의 범위(time period-기간)와 중요성(materiality)에 대한 지표(indicator)입니다.
주요 문자 필드(Key character field)도 테스트해야 합니다.
숫자 필드(Numeric Fields)
Statistics command(통계 명령)는 숫자 및 날짜(numeric & date) 필드 모두에 대해 풍부한 정보를 제공합니다.
숫자 필드(Numeric field)의 경우 다음 결과(result)를 빠르게 표시할 수 있습니다.
- Number/Total/Average(수/총계/평균)
- Number/Total/Average of positives(양의 개수/총계/평균)
- Number of zeros(0의 개수)
- Number/Total/Average of negatives(음의 개수/총계/평균)
- Absolute total(절대 값의 합계)
- Range(범위)
- Standard deviation(표준 편차)
- Top X(상위 X)
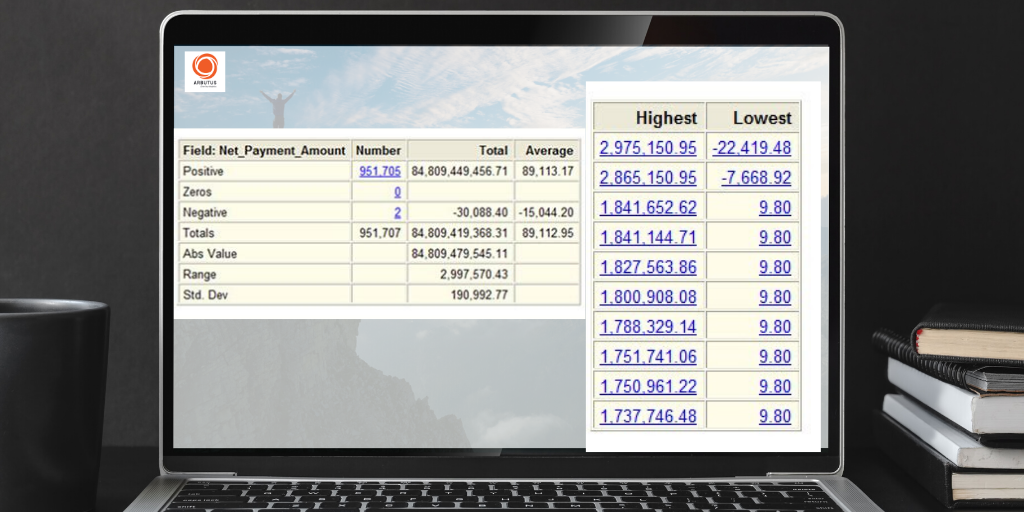
Outliers(이상치)을 테스트하기로 결정하는데 도움이 되도록 상위 X 결과를 검토하는 것이 항상 유용합니다.
날짜 필드(Date Fields)
Statistics command(통계 명령)은 다시 다음과 같은 중요한 결과(result)를 제공합니다.
- Blank dates(빈 날짜)
- Invalid dates(유효하지 않은 날짜)
- Weekend dates(주말 날짜)
- Range(범위)
- Top X dates(상위 X 날짜)
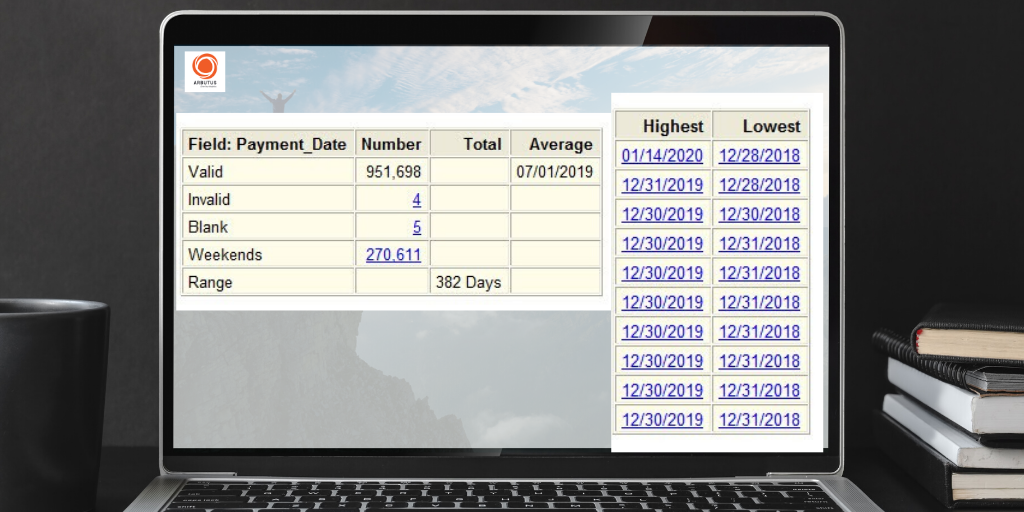
유효하지 않은 날짜(Invalid date)는 필드의 날짜 format 과 일치하지 않는 내용이 포함된 날짜입니다.
유효하지 않거나/비어 있는(Invalid/Blank) 날짜의 내용에 대한 세부 정보는 Verify command(검증 명령)으로 표시할 수 있습니다.
주말 날짜(Weekend dates)는 주말 또는 공휴일(weekend or holiday) 거래(transaction)가 고위험(high-risk)으로 간주되는 수동 분개(journal entries) 테스트에 유용할 수 있습니다.
Range(범위) 결과는 날짜의 범위를 즉시 확인합니다.
즉, 365보다 큰 범위는 레코드(records)가 1년 이상의 기간을 포함한다는 것을 알려줍니다.
상위 X 결과(result)를 검토하면 outliers(이상치)의 존재를 식별할 수 있습니다.
필터(Filter)를 사용하여 논리적으로 관련된(logically-related) 날짜 필드(date field)를 테스트하여, 주어진 레코드에서 payment date(지불 날짜) 이후에 invoice date(송장 날짜)가 나오는 것과 같은 비정상적인 것이 있는지 확인합니다.
Count command(명령)과 함께 필터(filter)를 사용하여, 그러한 것들의 존재 여부를 문서화합니다.
Count If Invoice_Date > Payment_Date
문자 필드(Character Fields): 기본 테스트(Basic Test)
문자 필드(Character field)는 복잡한 특성으로 인해 테스트를 위해 둘 이상의 command(명령)가 필요할 수 있습니다.
일부는 function(함수)이 포함된 필터(filter)와 함께 Count command(명령)를 사용하면 간단합니다.
- Blanks >> Count If IsBlank(<field name>)
- Short lengths >> Count If Length(Alltrim(<field name>)) < 3
문자 필드(Character Fields): Format 테스트
입력 유효성 검사(validation)가 빈약하거나 존재하지 않는 시스템의 경우, 데이터 format 이 일관될 것으로 예상되는 경우 character field(문자 필드) format 을 테스트하는 것이 유용합니다.
전화번호(phone number), 우편번호(postal code) 및 고객 ID 번호(custom ID number)와 같은 필드가 이러한 데이터의 예입니다.
Format function(포맷 함수)은 텍스트 필드(text field)의 기본 format 을 표시하므로 매우 유용합니다.
Classify command(분류 명령)과 함께 사용하면, 주어진 필드에 얼마나 많은 format 이 존재하는지 알 수 있습니다.
Format은 숫자(number)를 "9"로, 문자(character)를 "x" 또는 "X"(대소문자에 따라 다름)로 바꾸고 다른 모든 문자(character)를 표시합니다.
이 경우 vendor(공급업체) 데이터는 여러 소스에서 수집되었습니다.
데이터 입력 팀에게 숫자(digits-0에서 9까지의 아라비아 숫자)만 입력하라는 통보를 받았음에도 불구하고, Phone_Number(전화번호) 필드 데이터가 일관되지 않은 여러 format 으로 입력되었음을 알 수 있습니다.
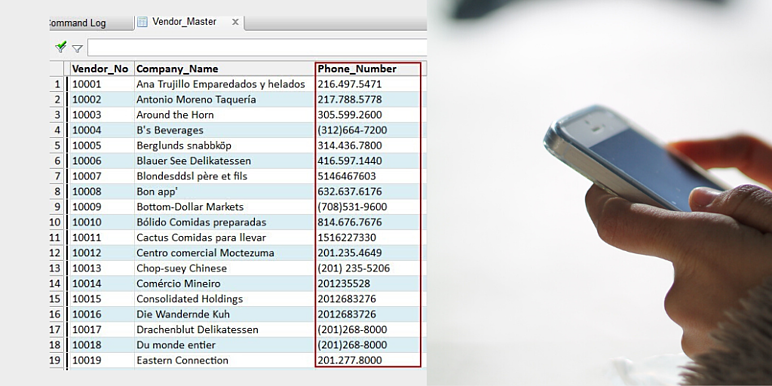
다양한 format 의 수(number)와 구조를 결정하기 위해, computed field(계산된 필드)를 만든 다음, Classify command(분류 명령)을 실행하여 사용 중인 format 의 수와 범위를 표시할 수 있습니다.
먼저, 기본 format 을 나타내는 computed field(계산된 필드)를 정의(define)합니다.
Edit >> Table Layout >> Add a New Expression 로 이동합니다.
새 필드(New field)의 이름을 Phone_Number_Format 으로 지정하고, "f(x)" 버튼을 클릭하여 Expression Builder(표현식 작성기)를 엽니다.
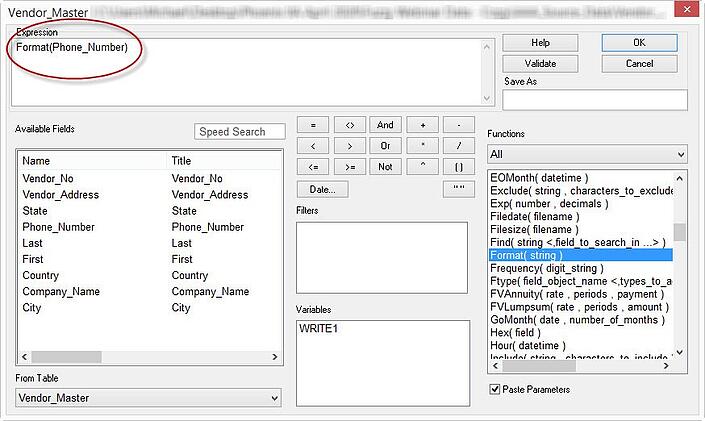
메인 dialog(대화상자)에서 Expression box(표현식 상자)에 Format(Phone_Number)을 입력하여 table layout 에 새 필드(new field)를 추가(add)합니다.
View(보기)로 돌아가서, Phone_Number 필드 옆에 새 필드(new field)를 추가(add)합니다.
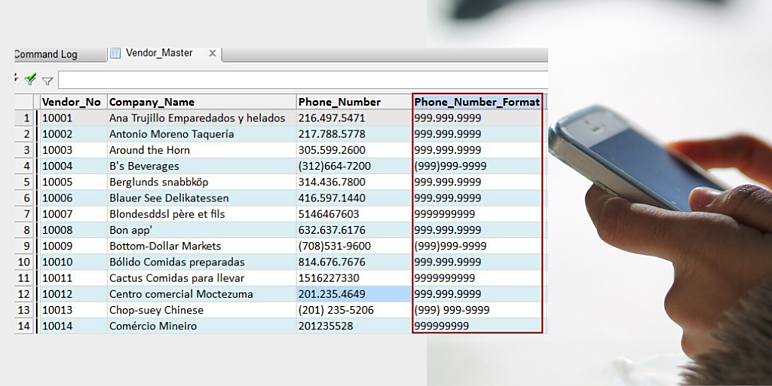
그런 다음, 새 필드(new field)에 대해 Classify command(분류 명령)을 실행합니다.
"TOP" parameter(매개 변수)를 지정하여, descending order of frequency(빈도의 내림차순)로 결과(result)를 sort(정렬)할 수 있습니다.
Output(출력)에 탐지된 모든 format 과 해당 number(번호)가 표시됩니다.
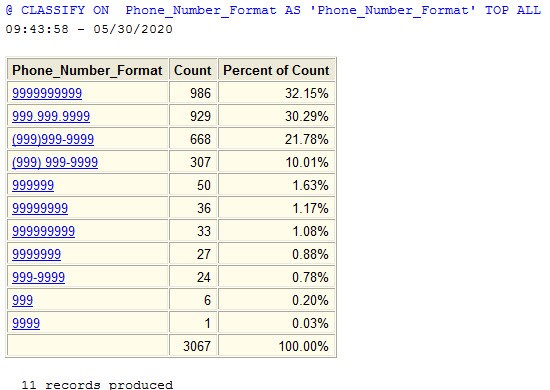
11개의 다른 format 이 발견되었습니다.
Duplicates(중복)을 검색하거나 다른 phone number(전화번호) 세트와 일치(match)시키기 위해 phone number(전화번호)를 harmonize(조화)시켜야 하는 경우, Include function(포함 함수)를 사용하는 Phone_Number_Clean 과 같은 computed field(계산된 필드)를 사용하면 됩니다.
Include (Phone_Number,"0~9")
이렇게 하면 숫자(numeric)를 제외한 모든 문자(character)를 제거(strip out)합니다.
10자리 숫자(ten digits)가 아닌 phone number(전화번호)의 존재를 추적해야 하는 경우, 다음 필터를 사용하여 관계된 레코드(record)를 다른 파일로 추출(extract)할 수 있습니다.
Length(Alltrim(Phone_Number_Clean)) <> 10

Sample Numeric Fields Output (샘플 숫자 필드 출력)
이것은 완전한 결과(result)를 보여주기 위해 두 개의 이미지로 분할되었습니다.

- 거래(Transaction) 파일을 열고 Join 명령을 시작합니다.
- "Secondary table" 목록에서 vendor master file(공급업체 마스터 파일)을 선택합니다.
- "Type of Join" 드롭다운(dropdown)에서 "Unmatched primary records only(일치되지 않은 기본 레코드만)"을 선택합니다.
- "Primary key fields" 목록에서 vendor number(공급업체 번호) 필드를 선택합니다.
- "Secondary key fields" 목록에서 vendor number(공급업체 번호) 필드를 선택합니다.
- "Primary fields to output" 목록에서 결과(result)에 필요한 모든 거래(transaction) 필드를 선택합니다.
- Output file(출력 파일)의 이름을 지정하고 "OK"를 클릭합니다. Output(출력)에는 master file(마스터 파일)에 일치(matching)하는 vendor number(공급업체 번호)가 없는 모든 지불 거래(payment transaction)가 포함됩니다.