

[기술적 해법(Technical Insights) | Simple Need Not Imply Simplistic]
원문 출처: https://www.arbutussoftware.com/en/technical-insights/simple-need-not-imply-simplistic
간단할 필요가 있다고 해서, 지나친 단순화를 의미하지는 않음
(Simple Need Not Imply Simplistic)
이것이 바로 Arbutus 가 추구하는 모든 것입니다.
Arbutus 가 기능 개발을 안내하는 원칙 중 하나는 복잡한 문제에 대한 간단한 솔루션을 제공해야 한다는 것입니다. 이러한 솔루션은 일반 사용자도 정교한 분석(sophisticated analysis)을 수행할 수 있도록 합니다.
다음은 Arbutus 가 간단한 솔루션으로 복잡한 문제를 해결하는 방법의 예입니다.
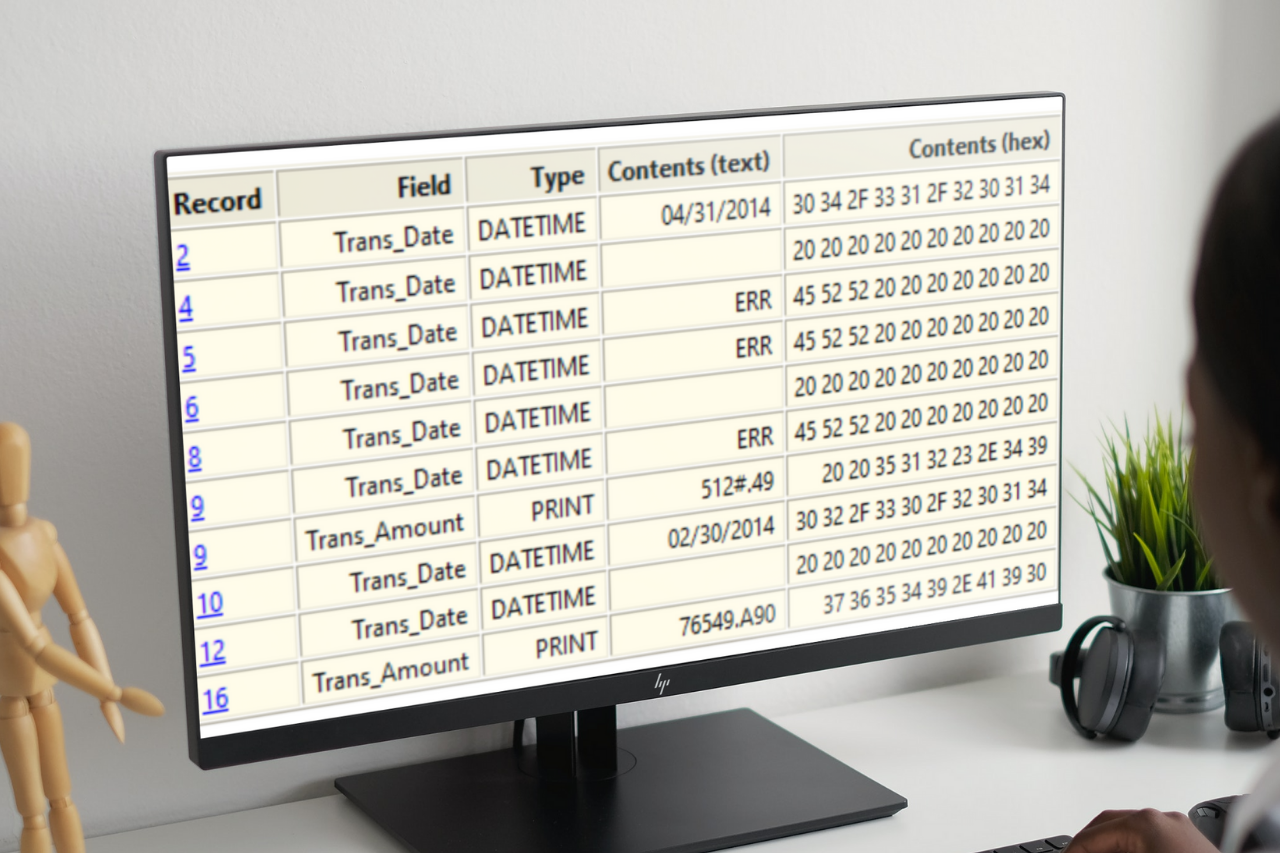
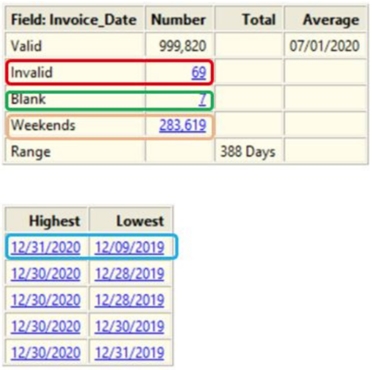
- 공백 날짜(Blank dates)
- 잘못된 날짜(내용이 비어 있지 않고 날짜가 아님)/Invalid dates (content is non-blank and not a date)
- 주말 날짜(Weekend dates)
- 가장 오래된 날짜와 최신 날짜(Oldest and newest dates)
- 범위(Range)
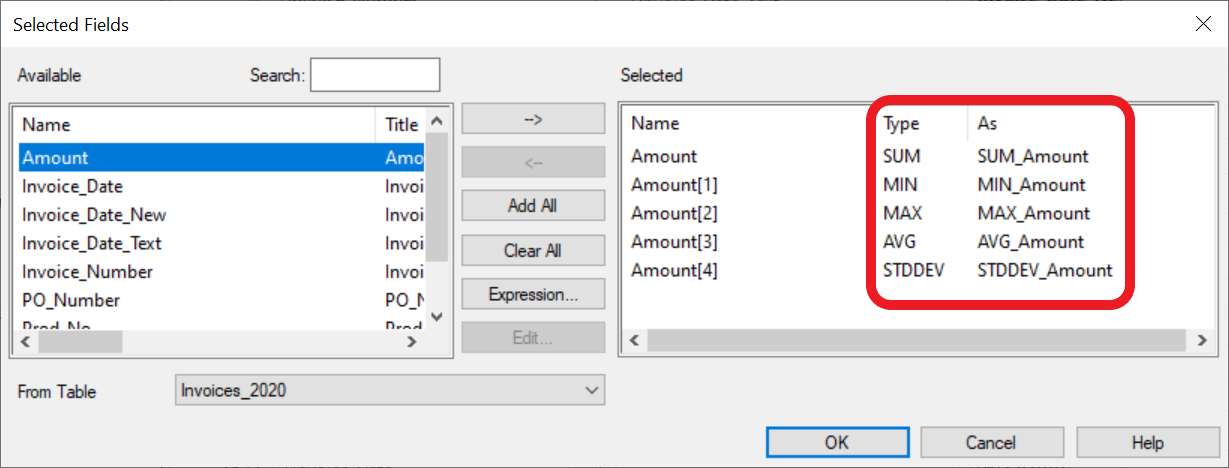
Same field(동일한 필드)를 여러 번 선택한 후 [Type]을 클릭해서 원하는 statistic(통계)로 변경합니다.
향상된 Summarize command(명령)는 "Fields to process(처리할 필드)" 목록에서 선택한 numeric field(숫자 필드)에 대해 다음 value(값)를 계산할 수 있습니다.
- First - key field 에 대해 정렬되는 데이터를 기준으로 첫 번째 value(값)
- Last - key field 에 대해 정렬되는 데이터를 기준으로 마지막으로 발생한 value(값)
- Sum - 선택한 숫자 열(numeric column)의 total(합계)
- Avg - 평균/average (or mean)
- Min - 최소값(minimum value)
- Max - 최대값(maximum value)
- StdDev - 표준 편차(standard deviation)
- Median - 중앙값
- Mode - 모드
- Q1 - 제1 사분위수
- Q3 - 제3 사분위수
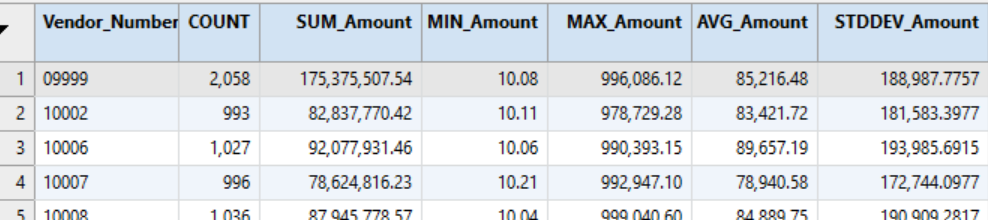
이것은 각 vendor(공급업체)의 invoice(송장) 집합(set)에 대한 statistics(통계)를 생성하여, 공급업체에 대한 payment(지불)에 대해 유용한 프로파일을 제공할 수 있습니다.
출력(Output)은 모집단(population) 전체가 아닌 각 vendor(공급업체)에 대한 2개의 표준 편차 임계값(standard deviations threshold)을 계산하여 outliers(이상치)를 식별하는데 사용할 수도 있습니다.
그런 다음 모집단 파일(population file)을 이 파일에 join 하여 각 공급업체의 임계값(threshold)을 캡처할 수 있습니다.
그런 다음 filter 는 임계값(threshold)보다 큰 각 vendor(공급업체)에 대한 payment(지불)를 식별합니다.
중복(Duplicates), True & Fuzzy
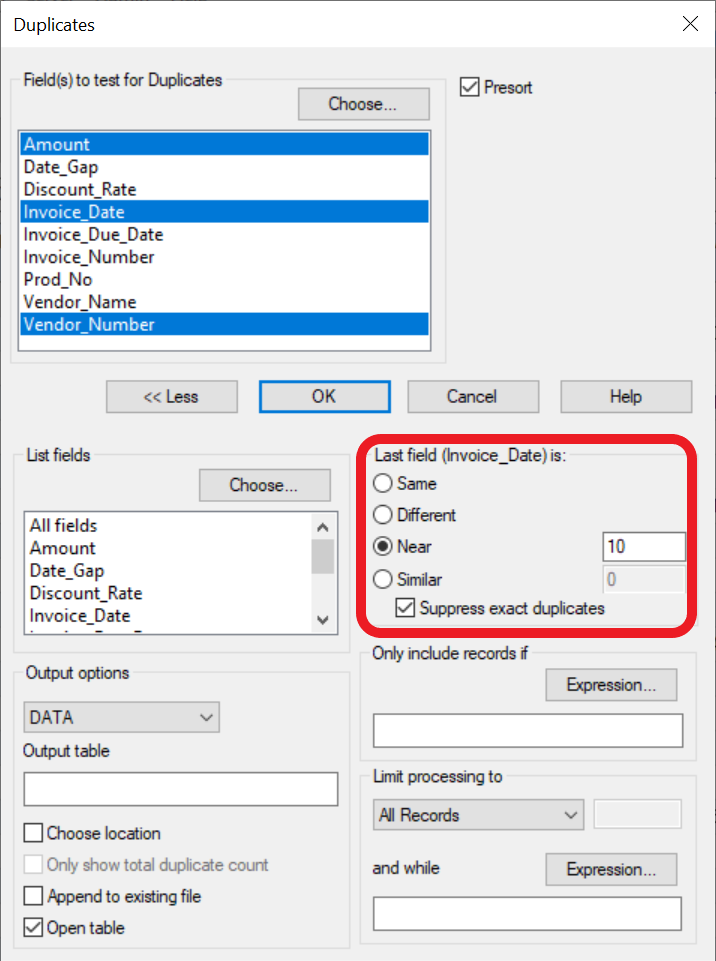
Duplicates 를 찾는 것은 표면적으로는 단순한 이진 작업(binary task)인 것처럼 보입니다: 두 가지가 같(same)거나 같지 않음.
그러나 감사인(auditor)과 다른 분석가(analyst)들에게는 세 번째 회색 영역이 존재합니다. 즉, 두 개 이상의 항목이 정확하게 duplicates(중복)되지 않고도 서로 상당히 유사할 수 있습니다.
- x days(x일) 이내에 same vendor(동일한 공급업체), same amount(동일한 금액)을 Duplicate payments(중복 지불);
- 한 문자(one-character) 차이가 있는 address(주소);
- "A165" 및 "AI65"와 같이 동일하게 보이지만, 다른 문자를 포함하는 account number(계좌 번호).
위 빨간색 직사각형 영역은 향상된 중복 탐지(duplicate detection)를 위한 다양한 옵션을 제공합니다.
이 경우 검색은 상호간 10일 이내의 same Vendor Number(동일한 공급업체 번호), same Amount 및 Invoice Date(동일한 금액 및 송장 날짜)를 검색하며, exact duplicates(정확한 중복 항목)는 출력(output)에서 제외됩니다.